How can I display a Regexp output in an Alphabetical list?
I suggest you construct your class as follows.
class Letter
def initialize(text) # 1
@text = text
end
def display
h = calculate_frequencies # 2
('a'..'z').each { |ltr|
puts "%s%s" % [ltr, '*' * h.fetch(ltr, 0)] } # 3
end
private # 4
def calculate_frequencies # 5
@text.downcase.
each_char. # 6
with_object(Hash.new(0)) { |c, letters| # 7
letters[c] += 1 if c.match?(/\p{Lower}/) } # 8
end
end
str = "Now is the time for all Rubyists to come to the aid of their bowling team."
ltr = Letter.new(str)
ltr.display
a***
b**
c*
d*
e******
f**
g*
h***
i******
j
k
l***
m***
n**
o*******
p
q
r***
s***
t********
u*
v
w**
x
y*
z
Notes
1
text should be an argument of initialize so the methods can be used for any string, rather than for just one hard-wired string. @letters should not be initialized here as it needs to be initialized in calculate_frequencies each time that method is called (and there it need not be an instance variable).
2
For str, calculate_frequencies returns
ltr.send(:calculate_frequencies)
#=> {"n"=>2, "o"=>7, "w"=>2, "i"=>6, "s"=>3, "t"=>8, "h"=>3, "e"=>6,
# "m"=>3, "f"=>2, "r"=>3, "a"=>3, "l"=>3, "u"=>1, "b"=>2, "y"=>1,
# "c"=>1, "d"=>1, "g"=>1}
Object#send invokes private methods, as well as ones that are public or protected.
3
See Hash#fetch and String#*.
4
All methods defined after the invocation of the keyword private are private, until and if the keyword public or protected is encountered. Alternatively, one can define a single private method as private def calculate_frequencies; ... ; end. Also a public (or protected) method m may be made private by executing private m.
5
One of Ruby's conventions is to use snake-case for names of variables and methods. You don't have to follow that convention but 99%+ of Rubyists do.
6
String#each_char returns an enumerator, whereas String#chars returns an array. The latter should only be used when an array is needed or it is chained to an Array method; otherwise, each_char is preferable because it does not create an unneeded temporary array.
7
See Enumerator#with_object.
8
Rather than matching everything other than spaces, you probably want to only match letters. Note how I've used if here to avoid the need for two statements. See String#match?. One could instead write c =~ /\p{Lower}/ or c[/\p{Lower}/]. \p{Lower} (or [[:lower:]]) matches any Unicode lower-case letter, which generally is preferable to /[a-z]/. Even for English text, one may encounter words having letters with diacritical marks, such as née, Señor, exposé and rosé. "é".match? /[a-z]/ #=> false but "é".match? /\p{Lower}/ #=> true. Search the doc Regexp for \p{Lower} and [[:lower:]].
Regular Expression to match only alphabetic characters
You may use any of these 2 variants:
/^[A-Z]+$/i
/^[A-Za-z]+$/
to match an input string of ASCII alphabets.
[A-Za-z]will match all the alphabets (both lowercase and uppercase).^and$will make sure that nothing but these alphabets will be matched.
Code:
preg_match('/^[A-Z]+$/i', "abcAbc^Xyz", $m);
var_dump($m);
Output:
array(0) {
}
Test case is for OP's comment that he wants to match only if there are 1 or more alphabets present in the input. As you can see in the test case that matches failed because there was ^ in the input string abcAbc^Xyz.
Note: Please note that the above answer only matches ASCII alphabets and doesn't match Unicode characters. If you want to match Unicode letters then use:
/^\p{L}+$/u
Here, \p{L} matches any kind of letter from any language
How can I use Regex to find a string of characters in alphabetical order using Python?
Just to demonstrate why regex is not practical for this sort of thing, here is a regex that would match ghiijk in your given example of abcghiijkyxz. Note it'll also match abc, y, x, z since they should technically be considered for longest string of alphabetical characters in order. Unfortunately, you can't determine which is the longest with regex alone, but this does give you all the possibilities. Please note that this regex works for PCRE and will not work with python's re module! Also, note that python's regex library does not currently support (*ACCEPT). Although I haven't tested, the pyre2 package (python wrapper for Google's re2 pyre2 using Cython) claims it supports the (*ACCEPT) control verb, so this may currently be possible using python.
See regex in use here
((?:a+(?(?!b)(*ACCEPT))|b+(?(?!c)(*ACCEPT))|c+(?(?!d)(*ACCEPT))|d+(?(?!e)(*ACCEPT))|e+(?(?!f)(*ACCEPT))|f+(?(?!g)(*ACCEPT))|g+(?(?!h)(*ACCEPT))|h+(?(?!i)(*ACCEPT))|i+(?(?!j)(*ACCEPT))|j+(?(?!k)(*ACCEPT))|k+(?(?!l)(*ACCEPT))|l+(?(?!m)(*ACCEPT))|m+(?(?!n)(*ACCEPT))|n+(?(?!o)(*ACCEPT))|o+(?(?!p)(*ACCEPT))|p+(?(?!q)(*ACCEPT))|q+(?(?!r)(*ACCEPT))|r+(?(?!s)(*ACCEPT))|s+(?(?!t)(*ACCEPT))|t+(?(?!u)(*ACCEPT))|u+(?(?!v)(*ACCEPT))|v+(?(?!w)(*ACCEPT))|w+(?(?!x)(*ACCEPT))|x+(?(?!y)(*ACCEPT))|y+(?(?!z)(*ACCEPT))|z+(?(?!$)(*ACCEPT)))+)
Results in:
abc
ghiijk
y
x
z
Explanation of a single option, i.e. a+(?(?!b)(*ACCEPT)):
a+Matchesa(literally) one or more times. This catches instances where several of the same characters are in sequence such asaa.(?(?!b)(*ACCEPT))If clause evaluating the condition.(?!b)Condition for the if clause. Negative lookahead ensuring what follows is notb. This is because if it's notb, we want the following control verb to take effect.(*ACCEPT)If the condition (above) is met, we accept the current solution. This control verb causes the regex to end successfully, skipping the rest of the pattern. Since this token is inside a capturing group, only that capturing group is ended successfully at that particular location, while the parent pattern continues to execute.
So what happens if the condition is not met? Well, that means that (?!b) evaluated to false. This means that the following character is, in fact, b and so we allow the matching (rather capturing in this instance) to continue. Note that the entire pattern is wrapped in (?:)+ which allows us to match consecutive options until the (*ACCEPT) control verb or end of line is met.
The only exception to this whole regular expression is that of z. Being that it's the last character in the English alphabet (which I presume is the target of this question), we don't care what comes after, so we can simply put z+(?(?!$)(*ACCEPT)), which will ensure nothing matches after z. If you, instead, want to match za (circular alphabetical order matching - idk if this is the proper terminology, but it sounds right to me) you can use z+(?(?!a)(*ACCEPT)))+ as seen here.
Alphabetic order regex using backreferences
I'm posting this answer more as a comment than an answer since it has better formatting than comments.
Related to your questions:
- Can I use back references in my character classes to check for ascending order strings?
No, you can't. If you take a look a backref regular-expressions section, you will find below documentation:
Parentheses and Backreferences Cannot Be Used Inside Character Classes
Parentheses cannot be used inside character classes, at least not as metacharacters. When you put a parenthesis in a character class, it is treated as a literal character. So the regex [(a)b] matches a, b, (, and ).
Backreferences, too, cannot be used inside a character class. The \1 in a regex like (a)[\1b] is either an error or a needlessly escaped literal 1. In JavaScript it's an octal escape.
Regarding your 2nd question:
- Is there any less-hacky solution to this puzzle?
Imho, your regex is perfectly well, you could shorten it very little at the beginning like this:
(?=^.{5}$)^a*b*c*d*e*f*g*h*i*j*k*l*m*n*o*p*q*r*s*t*u*v*w*x*y*z*$
^--- Here
Regex demo
Regular Expression for Alphabetical text with some exceptions
First, note that [A-z] is not the same as [A-Za-z], which is probably what you meant. If you look at an ASCII table, you can see that the range from A to z includes several special characters that you may not intend to include.
Second, since the dash - denotes a range in a character class (as above), it must be included last (or first, but more commonly last) in order to be interpreted as a literal dash.
So, what you really want is this:
/^[A-Za-z.()&-]+$/
And to assert that it starts with an alphabet:
/^[A-Za-z][A-Za-z.()&-]*$/
^^^^^^^^ ^
(Notice I've changed the + quantifer to a * quantifier.)
Finally, as @ExplosionPills had done, you can simplify the expression by making it case-insensitive:
/^[a-z][a-z.()&-]*$/i
PHP - regex check for all alphabet characters
You should use the builtin function http://php.net/manual/en/function.ctype-alpha.php for this purpose:
<?php
$strings = array('KjgWZC', 'arf12');
foreach ($strings as $testcase) {
if (ctype_alpha($testcase)) {
echo "The string $testcase consists of all letters.\n";
} else {
echo "The string $testcase does not consist of all letters.\n";
}
}
?>
The above example will output:
The string KjgWZC consists of all letters.
The string arf12 does not consist of all letters.
Source: PHP Manual
Regex for just alphabetic characters only - Java
Description
This regex will do the following:
- Assume words are entirely made up of alphabetical characters A-Z, upper case and lower case
- Find all words
- Ignore all strings that contain non-alphabetical characters or symbols
- Assumes some punctuation like periods or commas are to be ignored but the preceding word should be captured.
The Regex
(?<=\s|^)[a-zA-Z]*(?=[.,;:]?\s|$)
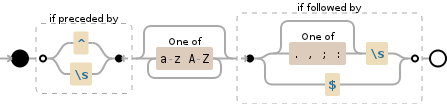
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
(?<= look behind to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
^ start of the string
----------------------------------------------------------------------
) end of look-behind
----------------------------------------------------------------------
[a-zA-Z]* any character of: 'a' to 'z', 'A' to 'Z'
(0 or more times (matching the most amount
possible))
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[.,;:]? any character of: '.', ',', ';', ':'
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
$ before an optional \n, and the end of
the string
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
Examples
Online Regex demo
http://fiddle.re/65eqna
Sample Java Code
import java.util.regex.Pattern;
import java.util.regex.Matcher;
class Module1{
public static void main(String[] asd){
String sourcestring = "source string to match with pattern";
Pattern re = Pattern.compile("(?<=\\s|^)[a-zA-Z]*(?=[.,;:]?\\s|$)");
Matcher m = re.matcher(sourcestring);
int mIdx = 0;
while (m.find()){
for( int groupIdx = 0; groupIdx < m.groupCount()+1; groupIdx++ ){
System.out.println( "[" + mIdx + "][" + groupIdx + "] = " + m.group(groupIdx));
}
mIdx++;
}
}
}
Sample Captures
$matches Array:
(
[0] => Array
(
[0] => To
[1] => find
[2] => the
[3] => golden
[4] => ticket
[5] => you
[6] => have
[7] => to
[8] => buy
[9] => a
[10] => bar
[11] => of
[12] => chocolate
[13] => Granny
[14] => and
[15] => Grandad
[16] => are
[17] => hoping
[18] => he
[19] => gets
[20] => a
[21] => ticket
[22] => but
[23] => he
[24] => only
[25] => has
[26] => enough
[27] => money
[28] => to
[29] => buy
[30] => bar
[31] => I
[32] => printed
[33] => tickets
[34] => but
[35] => my
[36] => workers
[37] => made
[38] => more
[39] => than
[40] => bars
)
)
Related Topics
There Is a Way to Handle 'After_Save' and 'After_Destroy' "Equally"
Why Do We Need Nginx with Thin on Production Setup
Rubocop, How to Disable/Enable Cops on Blocks of Code
Open-Uri Is Not Redirecing Http to Https
P Method in Ruby Hard to Search For
Sort by Date in Descending Order in Ruby in Rails
How to Link to a Page with Page.Url Without the HTML Extension in Jekyll
Where Are Catch and Throw Useful in Ruby
Regex for Matching All Words Between a Set of Curly Braces
Kernel_Require.Rb:55:In 'Require': Cannot Load Such File Error
How to Spec Methods That Exit or Abort
Rails: Allowing a Partial to Only Be Rendered Once
Ruby Tcpserver to Get Client Ip Address
Watir: Get Sometimes a Net::Readtimeout Error by Launching Chrome Browser
Capture Webcam's Image with Ruby
Find Out Which Words in a Large List Occur in a Small String