Most efficient way to search the last X lines of a file?
# Tail
from __future__ import with_statement
find_str = "FIREFOX" # String to find
fname = "g:/autoIt/ActiveWin.log_2" # File to check
with open(fname, "r") as f:
f.seek (0, 2) # Seek @ EOF
fsize = f.tell() # Get Size
f.seek (max (fsize-1024, 0), 0) # Set pos @ last n chars
lines = f.readlines() # Read to end
lines = lines[-10:] # Get last 10 lines
# This returns True if any line is exactly find_str + "\n"
print find_str + "\n" in lines
# If you're searching for a substring
for line in lines:
if find_str in line:
print True
break
Most efficient way to search very large text file and output lines matching any of a very large number of terms to another file
You might benefit from using a csv module to parse the data from the large file. It might also be overkill, and more trouble than it's worth, that you must judge for yourself. Be aware that Text::CSV_XS used below may alter your data to comply to csv standards, and there are many options to tweak what your output looks like.
This is a basic script that might get you started.
use strict;
use warnings;
use autodie;
use Text::CSV_XS;
open my $lookup, '<', "lookupfile";
my %lookup;
while (<$lookup>) {
next if /^\s*$/; # remove empty lines
chomp; # remove newline
$lookup{$_} = 1;
}
close $lookup;
my $csv = Text::CSV_XS->new ({
binary => 1,
eol => $/,
sep_char => "\t",
});
open my $bigfile, '<', 'bigfile';
while (my $row = $csv->getline ($bigfile)) {
if (defined ($lookup{$row->[0]})) {
$csv->print(\*STDOUT, $row);
}
}
If you feel secure that your data will not contain embedded tabs, you might get away with simply splitting the line on tabs, instead of using Text::CSV_XS:
while (<$bigfile>) {
chomp;
my @row = split /\t/;
if (defined $lookup{$row[0]}) {
print "$_\n";
}
}
What is the most efficient way to get first and last line of a text file?
docs for io module
with open(fname, 'rb') as fh:
first = next(fh).decode()
fh.seek(-1024, 2)
last = fh.readlines()[-1].decode()
The variable value here is 1024: it represents the average string length. I choose 1024 only for example. If you have an estimate of average line length you could just use that value times 2.
Since you have no idea whatsoever about the possible upper bound for the line length, the obvious solution would be to loop over the file:
for line in fh:
pass
last = line
You don't need to bother with the binary flag you could just use open(fname).
ETA: Since you have many files to work on, you could create a sample of couple of dozens of files using random.sample and run this code on them to determine length of last line. With an a priori large value of the position shift (let say 1 MB). This will help you to estimate the value for the full run.
Get last n lines or bytes of a huge file in Windows (like Unix's tail). Avoid time consuming options
How about this (reads last 8 bytes for demo):
$fpath = "C:\10GBfile.dat"
$fs = [IO.File]::OpenRead($fpath)
$fs.Seek(-8, 'End') | Out-Null
for ($i = 0; $i -lt 8; $i++)
{
$fs.ReadByte()
}
UPDATE. To interpret bytes as string (but be sure to select correct encoding - here UTF8 is used):
$N = 8
$fpath = "C:\10GBfile.dat"
$fs = [IO.File]::OpenRead($fpath)
$fs.Seek(-$N, [System.IO.SeekOrigin]::End) | Out-Null
$buffer = new-object Byte[] $N
$fs.Read($buffer, 0, $N) | Out-Null
$fs.Close()
[System.Text.Encoding]::UTF8.GetString($buffer)
UPDATE 2. To read last M lines, we'll be reading the file by portions until there are more than M newline char sequences in the result:
$M = 3
$fpath = "C:\10GBfile.dat"
$result = ""
$seq = "`r`n"
$buffer_size = 10
$buffer = new-object Byte[] $buffer_size
$fs = [IO.File]::OpenRead($fpath)
while (([regex]::Matches($result, $seq)).Count -lt $M)
{
$fs.Seek(-($result.Length + $buffer_size), [System.IO.SeekOrigin]::End) | Out-Null
$fs.Read($buffer, 0, $buffer_size) | Out-Null
$result = [System.Text.Encoding]::UTF8.GetString($buffer) + $result
}
$fs.Close()
($result -split $seq) | Select -Last $M
Try playing with bigger $buffer_size - this ideally is equal to expected average line length to make fewer disk operations. Also pay attention to $seq - this could be \r\n or just \n.
This is very dirty code without any error handling and optimizations.
Simple Way of NOT reading last N lines of a file in Python
Three different solutions:
1) Quick and dirty, see John's answer:
with open(file_name) as fid:
lines = fid.readlines()
for line in lines[:-n_skip]:
do_something_with(line)
The disadvantage of this method is that you have to read all lines in memory first, which might be a problem for big files.
2) Two passes
Process the file twice, once to count the number of lines n_lines, and in a second pass process only the first n_lines - n_skip lines:
# first pass to count
with open(file_name) as fid:
n_lines = sum(1 for line in fid)
# second pass to actually do something
with open(file_name) as fid:
for i_line in xrange(n_lines - n_skip): # does nothing if n_lines <= n_skip
line = fid.readline()
do_something_with(line)
The disadvantage of this method is that you have to iterate over the file twice, which might be slower in some cases. The good thing, however, is that you never have more than one line in memory.
3) Use a buffer, similar to Serge's solution
In case you want to iterate over the file just once, you only know for sure that you can process line i if you know that line i + n_skip exists. This means that you have to keep n_skip lines in a temporary buffer first. One way to do this is to implement some sort of FIFO buffer (e.g. with a generator function that implements a circular buffer):
def fifo(it, n):
buffer = [None] * n # preallocate buffer
i = 0
full = False
for item in it: # leaves last n items in buffer when iterator is exhausted
if full:
yield buffer[i] # yield old item before storing new item
buffer[i] = item
i = (i + 1) % n
if i == 0: # wrapped around at least once
full = True
Quick test with a range of numbers:
In [12]: for i in fifo(range(20), 5):
...: print i,
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
The way you would use this with your file:
with open(file_name) as fid:
for line in fifo(fid, n_skip):
do_something_with(line)
Note that this requires enough memory to temporary store n_skip lines, but this is still better than reading all lines in memory as in the first solution.
Which one of these 3 methods is the best is a trade-off between code complexity, memory and speed, which depends on your exact application.
Get last 10 lines of very large text file 10GB
Read to the end of the file, then seek backwards until you find ten newlines, and then read forward to the end taking into consideration various encodings. Be sure to handle cases where the number of lines in the file is less than ten. Below is an implementation (in C# as you tagged this), generalized to find the last numberOfTokens in the file located at path encoded in encoding where the token separator is represented by tokenSeparator; the result is returned as a string (this could be improved by returning an IEnumerable<string> that enumerates the tokens).
public static string ReadEndTokens(string path, Int64 numberOfTokens, Encoding encoding, string tokenSeparator) {
int sizeOfChar = encoding.GetByteCount("\n");
byte[] buffer = encoding.GetBytes(tokenSeparator);
using (FileStream fs = new FileStream(path, FileMode.Open)) {
Int64 tokenCount = 0;
Int64 endPosition = fs.Length / sizeOfChar;
for (Int64 position = sizeOfChar; position < endPosition; position += sizeOfChar) {
fs.Seek(-position, SeekOrigin.End);
fs.Read(buffer, 0, buffer.Length);
if (encoding.GetString(buffer) == tokenSeparator) {
tokenCount++;
if (tokenCount == numberOfTokens) {
byte[] returnBuffer = new byte[fs.Length - fs.Position];
fs.Read(returnBuffer, 0, returnBuffer.Length);
return encoding.GetString(returnBuffer);
}
}
}
// handle case where number of tokens in file is less than numberOfTokens
fs.Seek(0, SeekOrigin.Begin);
buffer = new byte[fs.Length];
fs.Read(buffer, 0, buffer.Length);
return encoding.GetString(buffer);
}
}
Get last n lines of a file, similar to tail
The code I ended up using. I think this is the best so far:
def tail(f, n, offset=None):
"""Reads a n lines from f with an offset of offset lines. The return
value is a tuple in the form ``(lines, has_more)`` where `has_more` is
an indicator that is `True` if there are more lines in the file.
"""
avg_line_length = 74
to_read = n + (offset or 0)
while 1:
try:
f.seek(-(avg_line_length * to_read), 2)
except IOError:
# woops. apparently file is smaller than what we want
# to step back, go to the beginning instead
f.seek(0)
pos = f.tell()
lines = f.read().splitlines()
if len(lines) >= to_read or pos == 0:
return lines[-to_read:offset and -offset or None], \
len(lines) > to_read or pos > 0
avg_line_length *= 1.3
Java : Read last n lines of a HUGE file
If you use a RandomAccessFile, you can use length and seek to get to a specific point near the end of the file and then read forward from there.
If you find there weren't enough lines, back up from that point and try again. Once you've figured out where the Nth last line begins, you can seek to there and just read-and-print.
An initial best-guess assumption can be made based on your data properties. For example, if it's a text file, it's possible the line lengths won't exceed an average of 132 so, to get the last five lines, start 660 characters before the end. Then, if you were wrong, try again at 1320 (you can even use what you learned from the last 660 characters to adjust that - example: if those 660 characters were just three lines, the next try could be 660 / 3 * 5, plus maybe a bit extra just in case).
What is the best way to read last lines (i.e. tail) from a file using PHP?
Methods overview
Searching on the internet, I came across different solutions. I can group them
in three approaches:
- naive ones that use
file()PHP function; - cheating ones that runs
tailcommand on the system; - mighty ones that happily jump around an opened file using
fseek().
I ended up choosing (or writing) five solutions, a naive one, a cheating one
and three mighty ones.
- The most concise naive solution,
using built-in array functions. - The only possible solution based on
tailcommand, which has
a little big problem: it does not run iftailis not available, i.e. on
non-Unix (Windows) or on restricted environments that don't allow system
functions. - The solution in which single bytes are read from the end of file searching
for (and counting) new-line characters, found here. - The multi-byte buffered solution optimized for large files, found
here. - A slightly modified version of solution #4 in which buffer length is
dynamic, decided according to the number of lines to retrieve.
All solutions work. In the sense that they return the expected result from
any file and for any number of lines we ask for (except for solution #1, that can
break PHP memory limits in case of large files, returning nothing). But which one
is better?
Performance tests
To answer the question I run tests. That's how these thing are done, isn't it?
I prepared a sample 100 KB file joining together different files found in
my /var/log directory. Then I wrote a PHP script that uses each one of the
five solutions to retrieve 1, 2, .., 10, 20, ... 100, 200, ..., 1000 lines
from the end of the file. Each single test is repeated ten times (that's
something like 5 × 28 × 10 = 1400 tests), measuring average elapsed
time in microseconds.
I run the script on my local development machine (Xubuntu 12.04,
PHP 5.3.10, 2.70 GHz dual core CPU, 2 GB RAM) using the PHP command line
interpreter. Here are the results:
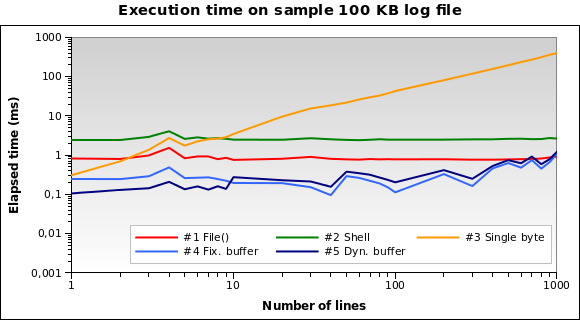
Solution #1 and #2 seem to be the worse ones. Solution #3 is good only when we need to
read a few lines. Solutions #4 and #5 seem to be the best ones.
Note how dynamic buffer size can optimize the algorithm: execution time is a little
smaller for few lines, because of the reduced buffer.
Let's try with a bigger file. What if we have to read a 10 MB log file?
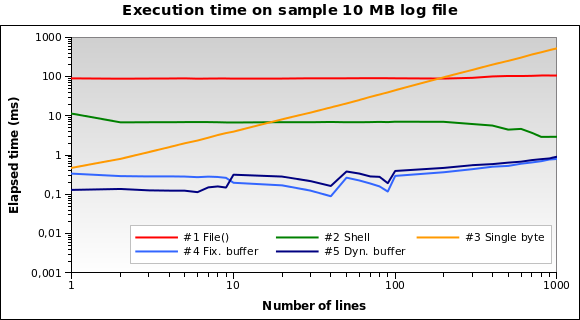
Now solution #1 is by far the worse one: in fact, loading the whole 10 MB file
into memory is not a great idea. I run the tests also on 1MB and 100MB file,
and it's practically the same situation.
And for tiny log files? That's the graph for a 10 KB file:
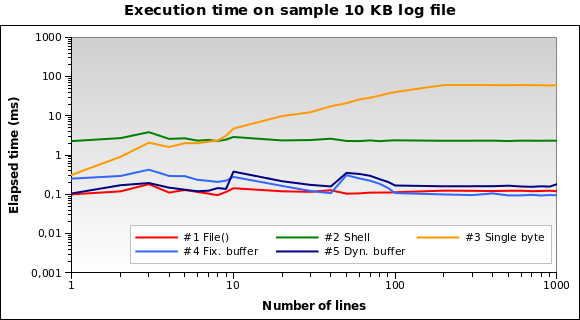
Solution #1 is the best one now! Loading a 10 KB into memory isn't a big deal
for PHP. Also #4 and #5 performs good. However this is an edge case: a 10 KB log
means something like 150/200 lines...
You can download all my test files, sources and results
here.
Final thoughts
Solution #5 is heavily recommended for the general use case: works great
with every file size and performs particularly good when reading a few lines.
Avoid solution #1 if you
should read files bigger than 10 KB.
Solution #2
and #3
aren't the best ones for each test I run: #2 never runs in less than
2ms, and #3 is heavily influenced by the number of
lines you ask (works quite good only with 1 or 2 lines).
Related Topics
Split an Integer into Digits to Compute an Isbn Checksum
Assigning String with Boolean Expression
Printing Without Newline (Print 'A',) Prints a Space, How to Remove
Best Way to Determine If a Sequence Is in Another Sequence
How to Remove Duplicates from a CSV File
How to Normalize a Url in Python
Python Method Name with Double-Underscore Is Overridden
What Does "\R" Do in the Following Script
What Is an 'Endpoint' in Flask
Does Python's Time.Time() Return the Local or Utc Timestamp
Pip Broke. How to Fix Distributionnotfound Error
Any Reason Not to Use '+' to Concatenate Two Strings
Fitting a 2D Gaussian Function Using Scipy.Optimize.Curve_Fit - Valueerror and Minpack.Error
Python:When Is a Variable Passed by Reference and When by Value