Text Mining R Package & Regex to handle Replace Smart Curly Quotes
Use two gsub operations: 1) to replace double curly quotes, 2) to replace single quotes:
> gsub("[“”]", "\"", gsub("[‘’]", "'", text))
[1] "You don't get \"your\" money's worth"
See the online R demo. Tested in both Linux and Windows, and works the same.
The [“”] construct is a positive character class that matches any single char defined in the class.
To normalize all chars similar to double quotes, you might want to use
> sngl_quot_rx = "[ʻʼʽ٬‘’‚‛՚︐]"
> dbl_quot_rx = "[«»““”„‟≪≫《》〝〞〟\"″‶]"
> res = gsub(dbl_quot_rx, "\"", gsub(sngl_quot_rx, "'", `Encoding<-`(text, "UTF8")))
> cat(res, sep="\n")
You don't get "your" money's worth
Here, [«»““”„‟≪≫《》〝〞〟"″‶] matches
« 00AB LEFT-POINTING DOUBLE ANGLE QUOTATION MARK
» 00BB RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK
“ 05F4 HEBREW PUNCTUATION GERSHAYIM
“ 201C LEFT DOUBLE QUOTATION MARK
” 201D RIGHT DOUBLE QUOTATION MARK
„ 201E DOUBLE LOW-9 QUOTATION MARK
‟ 201F DOUBLE HIGH-REVERSED-9 QUOTATION MARK
≪ 226A MUCH LESS-THAN
≫ 226B MUCH GREATER-THAN
《 300A LEFT DOUBLE ANGLE BRACKET
》 300B RIGHT DOUBLE ANGLE BRACKET
〝 301D REVERSED DOUBLE PRIME QUOTATION MARK
〞 301E DOUBLE PRIME QUOTATION MARK
〟 301F LOW DOUBLE PRIME QUOTATION MARK
" FF02 FULLWIDTH QUOTATION MARK
″ 2033 DOUBLE PRIME
‶ 2036 REVERSED DOUBLE PRIME
The [ʻʼʽ٬‘’‚‛՚︐] is used to normalize some chars similar to single quotes:
ʻ 02BB MODIFIER LETTER TURNED COMMA
ʼ 02BC MODIFIER LETTER APOSTROPHE
ʽ 02BD MODIFIER LETTER REVERSED COMMA
٬ 066C ARABIC THOUSANDS SEPARATOR
‘ 2018 LEFT SINGLE QUOTATION MARK
’ 2019 RIGHT SINGLE QUOTATION MARK
‚ 201A SINGLE LOW-9 QUOTATION MARK
‛ 201B SINGLE HIGH-REVERSED-9 QUOTATION MARK
՚ 055A ARMENIAN APOSTROPHE
︐ FE10 PRESENTATION FORM FOR VERTICAL COMMA
Use gsub to replace curly apostrophe with straight apostrophe in R list of character vectors
You might be running up against a bug in R on Windows. Try using utf8::as_utf8 on your input. Alternatively, this also works:
library(utf8)
list_TestWords <- as.list(c("this", "isn't", "ideal", "but", "we", "can’t", "fix", "it"))
lapply(list_TestWords, utf8_normalize, map_quote = TRUE)
This will replace the following characters with ASCII apostrophe:
U+055A ARMENIAN APOSTROPHE
U+2018 LEFT SINGLE QUOTATION MARK
U+2019 RIGHT SINGLE QUOTATION MARK
U+201B SINGLE HIGH-REVERSED-9 QUOTATION MARK
U+FF07 FULLWIDTH APOSTROPHE
It will also convert your text to composed normal form (NFC).
How to just remove (\) from string with (\) while keeping ()?
@Ronak Shah, @Chelmy88 and @Konrad Rudolph
helped me to understand where I was wrong in interpretation.
basically, it has to do with the way R renders the string in console.
Solution using cat() can resolve the confusion.
Python: Replace dumb quotation marks with “curly ones” in a string
You can use the HTMLParser to unescape the html entities returned from smartypants:
In [32]: from HTMLParser import HTMLParser
In [33]: s = "“But that gentleman,”"
In [34]: print HTMLParser().unescape(s)
“But that gentleman,”
In [35]: HTMLParser().unescape(s)
Out[35]: u'\u201cBut that gentleman,\u201d'
To avoin encoding errors, you should either use io.open when opening the file and specify encoding="the_encoding" or decode the strings to unicode:
In [11]: s
Out[11]: '“But that gentleman,”\xe2'
In [12]: print HTMLParser().unescape(s.decode("latin-1"))
“But that gentleman,”â
Getting linux command syntax with escaped quotes correct from R
If you chain the gsubs, you should pass message variable the second time. However, you may use it like this:
message <- gsub("\"", "\\\"", gsub("\'", "\\\'", input$mailAndStoreModalText, fixed=TRUE), fixed=TRUE)
Or a regex based replacement:
message <- gsub("([\"'])", "\\\\\\1", input$mailAndStoreModalText)
Both will output This\'s the \"best\" music as output.
See the R demo online. Note that cat(message, "\n") command shows you the literal string that message holds, not the string literal that you get when trying to just print message.
Also, the ([\"']) regex matches and captures into Group 1 either a " or ' and the "\\\\\\1" replacement pattern replaces the whole match with \ (that is defined with 4 backslashes) and then the value inside Group 1 (\\1).
Regex to match quote with minimum number of words
You need to "unroll" the character class by taking out the whitespace matching pattern out of it, and use a [<chars>]+(?:\s+[<chars>]+){4,} like pattern. Note you should not use lookarounds here because " can be both a leading and a trailing marker, and that may result in unwanted matches. Use a capturing group instead and access its value via matcher.group(1).
You may use
String regex = "[“\"]([A-Za-z0-9.-][A-Za-z,:’]*(?:\\s+[A-Za-z0-9.-][A-Za-z,:’]*){4,})[”\"]";
See the regex demo.
Then, just grab the Group 1 value:
String line = "Attorney General William Barr said the volume of information compromised was “staggering” and the largest breach in U.S. history.“This theft not only caused significant financial damage to Equifax but invaded the privacy of many, millions of Americans and imposed substantial costs and burdens on them as they had to take measures to protect themselves from identity theft,” said Mr. Barr.";
String regex = "[“\"]([A-Za-z0-9.-][A-Za-z,:’]*(?:\\s+[A-Za-z0-9.-][A-Za-z,:’]*){4,})[”\"]";
Matcher m = Pattern.compile(regex).matcher(line);
List<String> res = new ArrayList<>();
while(m.find()) {
res.add(m.group(1));
}
System.out.println(res);
See the online Java demo.
Pattern details
[“"]-“or"([A-Za-z0-9.-][A-Za-z,:’]*(?:\\s+[A-Za-z0-9.-][A-Za-z,:’]*){4,})- Group 1:[A-Za-z0-9.-][A-Za-z,:’]*- an ASCII alphanumeric or.or-and then 0+ of ASCII letters,,,:,’chars(?:\s+[A-Za-z0-9.-][A-Za-z,:’]*){4,}- four or more occurrences of\s+- 1+ whitespaces[A-Za-z0-9.-][A-Za-z,:’]*- an ASCII alphanumeric or.or-and then 0+ of ASCII letters,,,:,’chars
[”"]-"or”
regex for even no. of single quotes
We can use the following regex (count only ' not preceded by ").
\bAND\b(?=(?:(?:[^']*[^'"]'){2})*[^']*$)
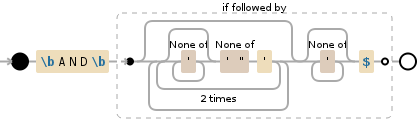
Debuggex Demo
Related Topics
Using Proxy Interface in Plotly/Shiny to Dynamically Change Data
Combine/Merge Columns While Avoiding Na
Install.Packages R on Ubuntu 12.04 Downloads But Does Not Install Packages
Convert String of Anyformat into Dd-Mm-Yy Hh:Mm:Ss in R
How to Convert Numeric Values to Time Without the Date
How to Run a High Pass or Low Pass Filter on Data Points in R
Contrasts Can Be Applied Only to Factor
Write.Table Writes Unwanted Leading Empty Column to Header When Has Rownames
How to Use Black-And-White Fill Patterns Instead of Color Coding on Calendar Heatmap
How to Replace Certain Values in a Specific Rows and Columns with Na in R
Add a Dynamic Value into Rmysql Getquery
Making Multiple Style References in Google Maps API
How to Replace Lower/Upper Triangular Elements of a Matrix
Logical Comparison of Two Vectors with Binary (0/1) Result
Graph Flow Chart of Transition from States
How to Rbind All the Data.Frames in Your Working Environment
Stacked Bar Chart, Reorder by Total (Sum Up of Values) Instead of Value Ggplot2 + Dplyr