PHP: How to read a file live that is constantly being written to
You need to loop with sleep:
$file='/home/user/youfile.txt';
$lastpos = 0;
while (true) {
usleep(300000); //0.3 s
clearstatcache(false, $file);
$len = filesize($file);
if ($len < $lastpos) {
//file deleted or reset
$lastpos = $len;
}
elseif ($len > $lastpos) {
$f = fopen($file, "rb");
if ($f === false)
die();
fseek($f, $lastpos);
while (!feof($f)) {
$buffer = fread($f, 4096);
echo $buffer;
flush();
}
$lastpos = ftell($f);
fclose($f);
}
}
PHP: How to constantly read a file
If your file have only one string, and you need to read it on change, use this code:
$file = '/path/to/test.txt';
$last_modify_time = 0;
while (true) {
sleep(1); // 1 s
clearstatcache(true, $file);
$curr_modify_time = filemtime($file);
if ($last_modify_time < $curr_modify_time) {
echo file_get_contents($file);
}
$last_modify_time = $curr_modify_time;
}
filemtime() returns last file modification time in seconds, so if you need to check modification more than one time per second, probably you'll need to find other solutions.
Also, you may need to add set_time_limit(0); it depends on your requirements.
Update:
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1/jquery.min.js"
type="text/javascript">
</script>
</head>
<body>
<div id="file_content"></div>
<script>
var time = 0;
setInterval(function() {
$.ajax({
type: "POST",
data: {time : time},
url: "fileupdate.php",
success: function (data) {
var result = $.parseJSON(data)
if (result.content) {
$('#file_content').append('<br>' + result.content);
}
time = result.time;
}
});
}, 1000);
</script>
</body>
<?php
$file = 'test.txt';
$result = array();
clearstatcache(true, $file);
$data['time'] = filemtime($file);
$data['content'] = $_POST['time'] < $data['time']
? file_get_contents($file)
: false;
echo json_encode($data);
How to read a log file live that is constantly updating in server to web textbox
Updated Answer
You can do this now using Web Socketing. Here is a guide and hello-wrold example of a php websocket server:
http://socketo.me/docs/hello-world
And to see how to implement client side javascript of websocket, you can see the bottom of the link put above, which shows you this snippet:
var conn = new WebSocket('ws://localhost:8080');
conn.onopen = function(e) {
console.log("Connection established!");
};
conn.onmessage = function(e) {
console.log(e.data);
};
Old
PHP does not support live connections generally in the way you expect, you have to simulate it via repeated AJAX request. How? For instance on each second, or each two seconds.
You first have to write an ajax in your HTML with jQuery library:
Sending a request each second:
var url = "url_to_you_file";
var textarea_id = "#textarea";
setInterval(function(){
$.ajax({
url : "site.com/get-file-logs.php",
type : "POST",
success : function(data){
$(".textarea").html(data);
}
});
}, 1000);
$file_path = "path_to_your_file";
$file_content = file_get_contents($file_path);
echo $file_content;
What is the best way to read last lines (i.e. tail) from a file using PHP?
Methods overview
Searching on the internet, I came across different solutions. I can group them
in three approaches:
- naive ones that use
file()PHP function; - cheating ones that runs
tailcommand on the system; - mighty ones that happily jump around an opened file using
fseek().
and three mighty ones.
- The most concise naive solution,
using built-in array functions. - The only possible solution based on
tailcommand, which has
a little big problem: it does not run iftailis not available, i.e. on
non-Unix (Windows) or on restricted environments that don't allow system
functions. - The solution in which single bytes are read from the end of file searching
for (and counting) new-line characters, found here. - The multi-byte buffered solution optimized for large files, found
here. - A slightly modified version of solution #4 in which buffer length is
dynamic, decided according to the number of lines to retrieve.
any file and for any number of lines we ask for (except for solution #1, that can
break PHP memory limits in case of large files, returning nothing). But which one
is better?
Performance tests
To answer the question I run tests. That's how these thing are done, isn't it?
I prepared a sample 100 KB file joining together different files found in
my /var/log directory. Then I wrote a PHP script that uses each one of the
five solutions to retrieve 1, 2, .., 10, 20, ... 100, 200, ..., 1000 lines
from the end of the file. Each single test is repeated ten times (that's
something like 5 × 28 × 10 = 1400 tests), measuring average elapsed
time in microseconds.
I run the script on my local development machine (Xubuntu 12.04,
PHP 5.3.10, 2.70 GHz dual core CPU, 2 GB RAM) using the PHP command line
interpreter. Here are the results:
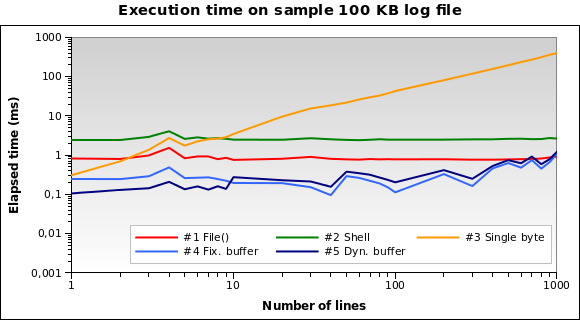
Solution #1 and #2 seem to be the worse ones. Solution #3 is good only when we need to
read a few lines. Solutions #4 and #5 seem to be the best ones.
Note how dynamic buffer size can optimize the algorithm: execution time is a little
smaller for few lines, because of the reduced buffer.
Let's try with a bigger file. What if we have to read a 10 MB log file?
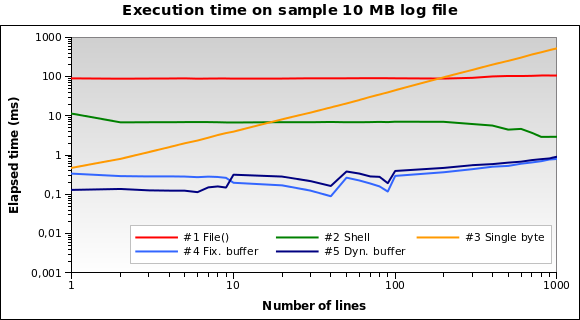
Now solution #1 is by far the worse one: in fact, loading the whole 10 MB file
into memory is not a great idea. I run the tests also on 1MB and 100MB file,
and it's practically the same situation.
And for tiny log files? That's the graph for a 10 KB file:
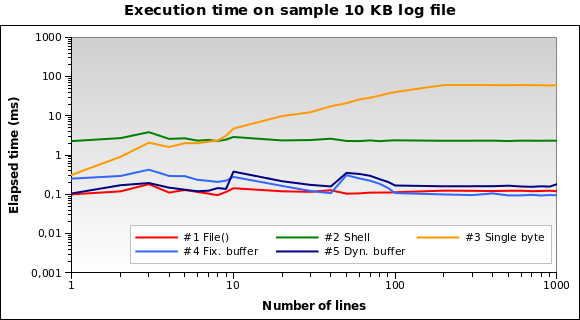
Solution #1 is the best one now! Loading a 10 KB into memory isn't a big deal
for PHP. Also #4 and #5 performs good. However this is an edge case: a 10 KB log
means something like 150/200 lines...
You can download all my test files, sources and results
here.
Final thoughts
Solution #5 is heavily recommended for the general use case: works great
with every file size and performs particularly good when reading a few lines.
Avoid solution #1 if you
should read files bigger than 10 KB.
Solution #2
and #3
aren't the best ones for each test I run: #2 never runs in less than
2ms, and #3 is heavily influenced by the number of
lines you ask (works quite good only with 1 or 2 lines).
Fastest way possible to read contents of a file
If you want to load the full-content of a file to a PHP variable, the easiest (and, probably fastest) way would be file_get_contents.
But, if you are working with big files, loading the whole file into memory might not be such a good idea : you'll probably end up with a memory_limit error, as PHP will not allow your script to use more than (usually) a couple mega-bytes of memory.
So, even if it's not the fastest solution, reading the file line by line (fopen+fgets+fclose), and working with those lines on the fly, without loading the whole file into memory, might be necessary...
Reading text after a specific character with PHP
$file=file('LauncherInfo.txt');
foreach ($file as $line) {
$line=str_replace(' = ','#',$line);
$line=preg_replace('%\r\n%','#',$line);
echo $line;
}
Related Topics
How to Get the Root Url of the Site
Upload Progress Using Pure PHP/Ajax
PHP Curl: Curlopt_Connecttimeout VS Curlopt_Timeout
SQL - Insert and Catch the Id Auto-Increment Value
How Would You Transform a Pre-Existing Web App into a Multilingual One
How to Use Laravel Passport with a Custom Username Column
PHP to Easyphp MySQL Server 1 Second Connection Delay
A Better Way to Replace Emoticons in PHP
PHP Exec() Command: How to Specify Working Directory
How to Put Double Quotes Inside a String Within an Ajax JSON Response from PHP
How to Check Is Timezone Identifier Valid from Code
PHP Script to Log the Raw Data of Post
Datetime Now PHP MySQL (+ Pdo Variant)