JavaScript regular expressions and sub-matches
I am surprised to see that I am the first person to answer this question with the answer I was looking for 10 years ago (the answer did not exist yet). I also was hoping that the actual spec writers would have answered it before me ;).
.matchAll has already been added to a few browsers.
In modern javascript we can now accomplish this by just doing the following.
let result = [...text.matchAll(/t(e)(s)t/g)];
.matchAll spec
.matchAll docs
I now maintain an isomorphic javascript library that helps with a lot of this type of string parsing. You can check it out here: string-saw. It assists in making .matchAll easier to use when using named capture groups.
An example would be
saw(text).matchAll(/t(e)(s)t/g)
Which outputs a more user-friendly array of matches, and if you want to get fancy you can throw in named capture groups and get an array of objects.
Getting all subgroups with a regex match
This problem isn't straightforward, but to understand why, you need to understand how the regular expression engine operates on your string.
Let's consider the pattern [a-z]{3} (match 3 successive characters between a and z) on the target string abcdef. The engine starts from the left side of the string (before the a), and sees that a matches [a-z], so it advances one position. Then, it sees that b matches [a-z] and advances again. Finally, it sees that c matches, advances again (to before d) and returns abc as a match.
If the engine is set up to return multiple matches, it will now try to match again, but it keeps its positional information (so, like above, it'll match and return def).
Because the engine has already moved past the b while matching abc, bcd will never be considered as a match. For this same reason, in your expression, once a group of words is matched, the engine will never consider words within the first match to be a part of the next one.
In order to get around this, you need to use capturing groups inside of lookaheads to collect matching words that appear later in the string:
var str = "2010 Women's Flat Track Derby Association",
regex = /([a-z0-9']+)(?=\s+([a-z0-9']+)\s+([a-z0-9']+))/ig,
match;
while (match = regex.exec(str))
{
var group1 = match[1], group2 = match[2], group3 = match[3];
console.log("Found match: " + group1 + " -- " + group2 + " -- " + group3);
}JS - String includes a substring that matches regex
You can use .test() on your regular expression to check whether the pattern matches part of the string. As the pattern will need to match only a portion of the string, you will need to remove the ^ and $ characters as your matched pattern can be contained within a line. Also, there is no need to escape the character class bracket as you have tried to do so in your expression (\[), as you want the [ to be treated as a character class, not a literal square bracket:
const myString = "This is my test string: AA.12.B.12 with some other chars";const res = /[A-Z]{2}\.\d{2}\.[A-Z]{1}\.\d{2,3}/.test(myString);console.log(res);JavaScript regexp repeating (sub)group
This is impossible to do in one regular expression. JavaScript Regex will only return to you the last matched group which is exactly your problem. I had this seem issue a while back: Regex only capturing last instance of capture group in match. You can get this to work in .Net, but that's probably not what you need.
I'm sure you can figure out how to do this in a regular expressions, and the spit the arguments from the second group.
\{\{(\w+)\s+(.*?)\}\}
Here's some javaScript code to show you how it's done:
var input = $('#input').text();
var regex = /\{\{(\w+)\s*(.*?)\}\}/g;
var match;
var attribs;
var kvp;
var output = '';
while ((match = regex.exec(input)) != null) {
output += match[1] += ': <br/>';
if (match.length > 2) {
attribs = match[2].split(/\s+/g);
for (var i = 0; i < attribs.length; i++) {
kvp = attribs[i].split(/\s*=\s*/);
output += ' - ' + kvp[0] + ' = ' + kvp[1] + '<br/>';
}
}
}
$('#output').html(output);
jsFiddle
A crazy idea would be to use a regex and replace to convert your code into json and then decode with JSON.parse. I know the following is a start to that idea.
/[\s\S]*?(?:\{\{(\w+)\s+(.*?)\}\}|$)/g.replace(input, doReplace);
function doReplace ($1, $2, $3) {
if ($2) {
return "'" + $2 + "': {" +
$3.replace(/\s+/g, ',')
.replace(/=/g, ':')
.replace(/(\w+)(?=:)/g, "'$1'") + '};\n';
}
return '';
}
REY
How can I match multiple occurrences with a regex in JavaScript similar to PHP's preg_match_all()?
Hoisted from the comments
2020 comment: rather than using regex, we now have
URLSearchParams, which does all of this for us, so no custom code, let alone regex, are necessary anymore.– Mike 'Pomax' Kamermans
Browser support is listed here https://caniuse.com/#feat=urlsearchparams
I would suggest an alternative regex, using sub-groups to capture name and value of the parameters individually and re.exec():
function getUrlParams(url) {
var re = /(?:\?|&(?:amp;)?)([^=&#]+)(?:=?([^&#]*))/g,
match, params = {},
decode = function (s) {return decodeURIComponent(s.replace(/\+/g, " "));};
if (typeof url == "undefined") url = document.location.href;
while (match = re.exec(url)) {
params[decode(match[1])] = decode(match[2]);
}
return params;
}
var result = getUrlParams("http://maps.google.de/maps?f=q&source=s_q&hl=de&geocode=&q=Frankfurt+am+Main&sll=50.106047,8.679886&sspn=0.370369,0.833588&ie=UTF8&ll=50.116616,8.680573&spn=0.35972,0.833588&z=11&iwloc=addr");
result is an object:
{
f: "q"
geocode: ""
hl: "de"
ie: "UTF8"
iwloc: "addr"
ll: "50.116616,8.680573"
q: "Frankfurt am Main"
sll: "50.106047,8.679886"
source: "s_q"
spn: "0.35972,0.833588"
sspn: "0.370369,0.833588"
z: "11"
}
The regex breaks down as follows:
(?: # non-capturing group
\?|& # "?" or "&"
(?:amp;)? # (allow "&", for wrongly HTML-encoded URLs)
) # end non-capturing group
( # group 1
[^=&#]+ # any character except "=", "&" or "#"; at least once
) # end group 1 - this will be the parameter's name
(?: # non-capturing group
=? # an "=", optional
( # group 2
[^&#]* # any character except "&" or "#"; any number of times
) # end group 2 - this will be the parameter's value
) # end non-capturing group
Repeated Capturing Matching Groups (Submatches)
package main
import (
"reflect"
"regexp"
"testing"
)
func TestParseCalcExpression(t *testing.T) {
re := regexp.MustCompile(`(\d+)([*/+-]?)`)
for _, eg := range []struct {
input string
expected [][]string
}{
{"1", [][]string{{"1", "1", ""}}},
{"1+1", [][]string{{"1+", "1", "+"}, {"1", "1", ""}}},
{"22/7", [][]string{{"22/", "22", "/"}, {"7", "7", ""}}},
{"1+2+3", [][]string{{"1+", "1", "+"}, {"2+", "2", "+"}, {"3", "3", ""}}},
{"2*3+5/6", [][]string{{"2*", "2", "*"}, {"3+", "3", "+"}, {"5/", "5", "/"}, {"6", "6", ""}}},
} {
actual := re.FindAllStringSubmatch(eg.input, -1)
if !reflect.DeepEqual(actual, eg.expected) {
t.Errorf("expected parse(%q)=%#v, got %#v", eg.input, eg.expected, actual)
}
}
}
Playground link
As mentioned in this question about Swift (I'm not a Swift or regex expert so I'm just guessing this applies to Go as well), you can only return one match for each matching group in your regex. It seems to just identify the last match if the group is repeating.
From the Go standard library regexp package documentation:
If 'Submatch' is present, the return value is a slice identifying the successive submatches of the expression. Submatches are matches of parenthesized subexpressions (also known as capturing groups) within the regular expression, numbered from left to right in order of opening parenthesis. Submatch 0 is the match of the entire expression, submatch 1 the match of the first parenthesized subexpression, and so on.
Given this convention, returning multiple matches per match group would break the numbering and therefore you wouldn't know which items were associated with each matching group. It seems it's possible that a regex engine could return multiple matches per group, but this package couldn't do that without breaking this convention stated in the documentation.
My solution is to make your problem more regular. Instead of treating the entire expression as one match, which gave us the problem that we can only return finitely many strings per match, we treat the entire expression as simply a series of pairs.
Each pair is composed of a number (\d+), and an optional operator ([*/+-]?).
Then doing a FindAllStringSubmatch on the whole expression, we extract a series of these pairs and get the number and operator for each.
For example:"1+2+3"
returns[][]string{{"1+", "1", "+"}, {"2+", "2", "+"}, {"3", "3", ""}}}
This only tokenizes the expression; it doesn't validate it. If you need the expression to be validated, then you'll need another initial regex match to verify that the string is indeed an unbroken series of these pairs.
JavaScript Regex Global Match Groups
To do this with a regex, you will need to iterate over it with .exec() in order to get multiple matched groups. The g flag with match will only return multiple whole matches, not multiple sub-matches like you wanted. Here's a way to do it with .exec().
var input = "'Warehouse','Local Release','Local Release DA'";
var regex = /'(.*?)'/g;
var matches, output = [];
while (matches = regex.exec(input)) {
output.push(matches[1]);
}
// result is in output here
Working demo: http://jsfiddle.net/jfriend00/VSczR/
With certain assumptions about what's in the strings, you could also just use this:
var input = "'Warehouse','Local Release','Local Release DA'";
var output = input.replace(/^'|'$/, "").split("','");
Working demo: http://jsfiddle.net/jfriend00/MFNm3/
Note: With modern Javascript engines as of 2021, you can use str.matchAll(regex) and get all matches in one function call.
Regex to match multiple different sub-strings in a given input string
Your regex starts off with a start-of-string anchor (^). This causes the regex to only match at the start of your string. Since "v(def" is not at the start of the input string "value(abc) or v(def) or s(xyz)", the regex will not match it. Removing the start-of-string anchor will fix this.
In addition, the two alternatives in your regex are mostly the same, aside from some additional characters in the first alternative. Your regex could be simplified to the following:
v(?:alue)?\(

Update: To get the value of the expression inside of the parenthesis, you can use a capturing group (surround an expression with ()). Capturing groups are numbered based on the position of their opening parenthesis. The group whose ( comes first is group "1", the second ( is group "2", and so on. Depending on what regex engine you are using, you might also be able to use named capturing groups (?<name>...) (I know .NET supports them). You would then use your engine's method of retrieving the value of a capturing group.
For example, the following regex will match:
vorvalue- an opening
( - an optional value made up of alphabetic characters
- a closing
)
The optional value will be stored in the "value" capturing group. You will want to change the expression inside the value group to match the format of your values.
v(?:alue)?\((?<value>[a-zA-Z]*)\)
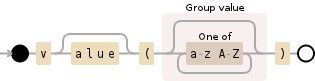
(Visualizations created using Debuggex)
JavaScript Regex: How to split Regex subexpression matches in to multi-dimensional string arrays?
You didn't say what the exact output you expect, but I imagine something like this output may be intuitive.
Given:
var myvar = "1-4:2;5-9:1.89;10-24:1.79;25-99:1.69;100-149:1.59;150-199:1.49;200-249:1.39;250+:1.29";
A quick way to capture all sub-matches is:
var matches = [];
myvar.replace(/(\d+)[-+](\d*):(\d+\.?\d*);?/g, function(m, a, b, c) {
matches.push([a, b, c])
});
(Note: you can capture the same output with a [potentially more readable] loop):
var myreg = /(\d+)[-+](\d*):(\d+\.?\d*);?/g;
var matches = [];
while(myreg.exec(myvar)) {
matches.push([RegExp.$1, RegExp.$2, RegExp.$3])
}
Either way, the outcome is an array of matches:
matches[0]; // ["1", "4", "2"]
matches[1]; // ["5", "9", "1.89"]
matches[2]; // ["10", "24", "1.79"]
matches[3]; // ["25", "99", "1.69"]
matches[4]; // ["100", "149", "1.59"]
matches[5]; // ["150", "199", "1.49"]
matches[6]; // ["200", "249", "1.39"]
matches[7]; // ["250", "", "1.29"]
Related Topics
Calling Setstate in a Loop Only Updates State 1 Time
Node.Js Shell Command Execution
Check If Object Is a Jquery Object
Detecting Line-Breaks with Jquery
Difference and Intersection of Two Arrays Containing Objects
Componentdidmount Equivalent on a React Function/Hooks Component
How to Print a Stack Trace in Node.Js
How to Perform an Http File Upload Using Express on Cloud Functions for Firebase (Multer, Busboy)
Which Edition of Ecma-262 Does Google Apps Script Support
Differencebetween & VS @ and = in Angularjs
Node.Js Tail-Call Optimization: Possible or Not
Difference Between Dom Parentnode and Parentelement
Finding Longest String in Array
How to Parse a Url Query Parameters, in JavaScript
JavaScript Decoding HTML Entities
Angular2 Dynamic Input Field Lose Focus When Input Changes
How to Check Whether an Object Is a Date
Getting Error "Form Submission Canceled Because the Form Is Not Connected"