boolean[] vs. BitSet: Which is more efficient?
From some benchmarks with Sun JDK 1.6 computing primes with a sieve (best of 10 iterations to warm up, give the JIT compiler a chance, and exclude random scheduling delays, Core 2 Duo T5600 1.83GHz):
BitSet is more memory efficient than boolean[] except for very small sizes. Each boolean in the array takes a byte. The numbers from runtime.freeMemory() are a bit muddled for BitSet, but less.
boolean[] is more CPU efficient except for very large sizes, where they are about even. E.g., for size 1 million boolean[] is about four times faster (e.g. 6ms vs 27ms), for ten and a hundred million they are about even.
Is BitSet worth using?
Nice space comparison here between boolean[] and BitSet:
https://www.baeldung.com/java-boolean-array-bitset-performance
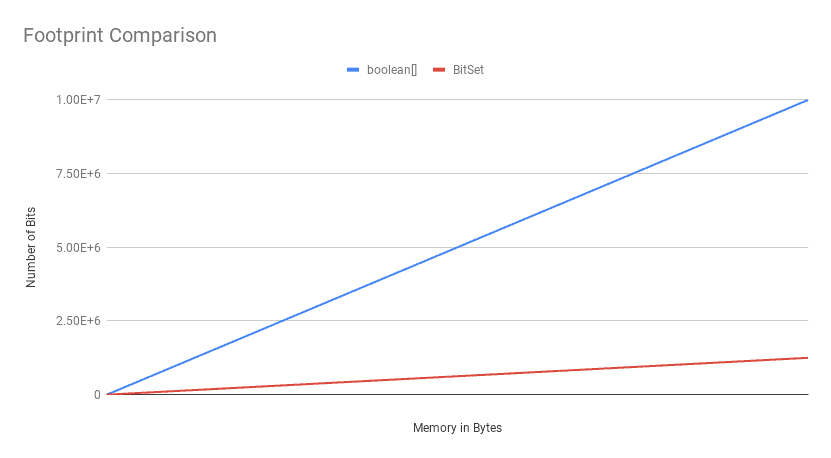
Think they swapped labels here. Should be more bits per memory (Blue) in BitSet.
The key takeaway here is, the BitSet beats the boolean[] in terms of the memory footprint, except for a minimal number of bits.
An alternative in your example is to use 2 long as bit flags.
class A {
// 1st set
private static final long IS_VISIBLE_MASK = 1;
...
private static final long IS_DARK_MASK = 1 << 63 ;
// 2nd set...
private static final long IS_TASTY_MASK = 1;
...
// IS_VISIBLE_MASK .. IS_DARK_MASK
long data1;
// IS_TASTY_MASK ...
long data2;
boolean isDark = (data1 & IS_DARK_MASK) != 0;
}
Limitations
BitSet comes with silly limitations, as you can reach a max of Integer.MAX_VALUE bits. I needed as much bits as I could store in RAM. So modified the original implementation in two ways:
- It waste less computing for fixed sized LongBitSets (i.e. user specifies length at construction time).
- it can reach the last bit in the biggest possible word array.
Added details on limitations in this thread
Java : Difference between a boolean array & BitSet?
The documentation for a BitSet pretty clearly implies that the implementation isn't necessarily an actual boolean array. In particular:
Every bit set has a current size, which is the number of bits of space
currently in use by the bit set. Note that the size is related to the
implementation of a bit set, so it may change with implementation. The
length of a bit set relates to logical length of a bit set and is
defined independently of implementation.
The source for Java library classes is openly available and you can easily check this for yourself. In particular:
The internal field corresponding to the serialField "bits".
89
90 private long[] words;
As for speed; profile it. It depends on what you are doing. In general, don't think about speed ahead of time; use whichever tool makes the most sense semantically and leads to the clearest code. Optimize only after observing that your performance requirements aren't being met and identifying the bottlenecks.
In any case, obviously, I'd presume that a direct access to a value in a boolean array is faster than finding the bit in a long array, but performing a bitwise OR on two long values is faster than performing a logical OR on 64 boolean values. Think about it a little. For example:
613 public boolean get(int bitIndex) {
614 if (bitIndex < 0)
615 throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
616
617 checkInvariants();
618
619 int wordIndex = wordIndex(bitIndex);
620 return (wordIndex < wordsInUse)
621 && ((words[wordIndex] & (1L << bitIndex)) != 0);
622 }
As for other differences, obviously the API is different. BitSet provides a number of bitwise operations that you may need to use. A boolean array is an array. The one that works best for you will depend on your specific application requirements.
Where do we use BitSet and why do we use it in java?
As the above answer only explains what a BitSet is, I am providing here an answer of how I use BitSet and why. At first, I did not knew that the BitSet construct exists. I have a QR Code generator in C++ and for flexible reasons I don't want to use a specific Bitmap structures in returning this QR Code back to the caller. The QR Code is just black and white and can be represented as a series of bits. The problem was that in the JNI C++, I have to return the byte array that represents these series of bits and then I have to return the count of bits. Note that the size of the bytes array alone could not tell the count of bits. In effect, I am face with a scenario wherein my JNI C++ has to return two values:
- the byte[] array
- the count of bits
My first solution, was to return an array of boolean. The content of this array are the QR Code pixels, and the square root of the length of the array is the length of the side. Of course this worked but I felt wasted because it is supposed to be a series of bits. My next attempt was to return Pair<int, byte[]> object which, after lots of hair pulling i am not able to make it work in C++. Here comes the BitSet(145) construct. By returning this BitSet object, I am conveying two types of information i listed above. But there is minor trick. If QR Code pixel has total 144 pixels, because one side is 12, then you have to allocate BitSet(145) and do obj.set(144). That is, we introduce an artificial last bit that we then set, but this last bit is not part of the QR Code pixels. This ensures that, BitSet::length() correctly returns the bit count. So in Kotlin:
var pixels:BitSet = getqrpixels(inputdata)
var pixels_len = pixels.length() - 1
var side = sqrt(pixels_len.toFloat()).toInt()
drawSquareBitmap(pixels, side)
And thus, is my unexpected use case of this mysterious BitSet.
Why would you use a BitSet in java as opposed to an array of booleans (in Java)?
You would do it to save space: a boolean occupies a whole byte, so an array of N booleans would occupy eight times the space of a BitSet with the equivalent number of entries.
Execution speed is another closely related concern: you can produce a union or an intersection of several BitSet objects faster, because these operations can be performed by CPU as bitwise ANDs and ORs on 32 bits at a time.
What is the performance of std::bitset?
Update
It's been ages since I posted this one, but:
I already know that it is easier and clearer than bit-fiddling on an
integer, but is it as fast?
If you are using bitset in a way that does actually make it clearer and cleaner than bit-fiddling, like checking for one bit at a time instead of using a bit mask, then inevitably you lose all those benefits that bitwise operations provide, like being able to check to see if 64 bits are set at one time against a mask, or using FFS instructions to quickly determine which bit is set among 64-bits.
I'm not sure that bitset incurs a penalty to use in all ways possible (ex: using its bitwise operator&), but if you use it like a fixed-size boolean array which is pretty much the way I always see people using it, then you generally lose all those benefits described above. We unfortunately can't get that level of expressiveness of just accessing one bit at a time with operator[] and have the optimizer figure out all the bitwise manipulations and FFS and FFZ and so forth going on for us, at least not since the last time I checked (otherwise bitset would be one of my favorite structures).
Now if you are going to use bitset<N> bits interchangeably with like, say, uint64_t bits[N/64] as in accessing both the same way using bitwise operations, it might be on par (haven't checked since this ancient post). But then you lose many of the benefits of using bitset in the first place.
for_each method
In the past I got into some misunderstandings, I think, when I proposed a for_each method to iterate through things like vector<bool>, deque, and bitset. The point of such a method is to utilize the internal knowledge of the container to iterate through elements more efficiently while invoking a functor, just as some associative containers offer a find method of their own instead of using std::find to do a better than linear-time search.
For example, you can iterate through all set bits of a vector<bool> or bitset if you had internal knowledge of these containers by checking for 64 elements at a time using a 64-bit mask when 64 contiguous indices are occupied, and likewise use FFS instructions when that's not the case.
But an iterator design having to do this type of scalar logic in operator++ would inevitably have to do something considerably more expensive, just by the nature in which iterators are designed in these peculiar cases. bitset lacks iterators outright and that often makes people wanting to use it to avoid dealing with bitwise logic to use operator[] to check each bit individually in a sequential loop that just wants to find out which bits are set. That too is not nearly as efficient as what a for_each method implementation could do.
Double/Nested Iterators
Another alternative to the for_each container-specific method proposed above would be to use double/nested iterators: that is, an outer iterator which points to a sub-range of a different type of iterator. Client code example:
for (auto outer_it = bitset.nbegin(); outer_it != bitset.nend(); ++outer_it)
{
for (auto inner_it = outer_it->first; inner_it != outer_it->last; ++inner_it)
// do something with *inner_it (bit index)
}
While not conforming to the flat type of iterator design available now in standard containers, this can allow some very interesting optimizations. As an example, imagine a case like this:
bitset<64> bits = 0x1fbf; // 0b1111110111111;
In that case, the outer iterator can, with just a few bitwise iterations ((FFZ/or/complement), deduce that the first range of bits to process would be bits [0, 6), at which point we can iterate through that sub-range very cheaply through the inner/nested iterator (it would just increment an integer, making ++inner_it equivalent to just ++int). Then when we increment the outer iterator, it can then very quickly, and again with a few bitwise instructions, determine that the next range would be [7, 13). After we iterate through that sub-range, we're done. Take this as another example:
bitset<16> bits = 0xffff;
In such a case, the first and last sub-range would be [0, 16), and the bitset could determine that with a single bitwise instruction at which point we can iterate through all set bits and then we're done.
This type of nested iterator design would map particularly well to vector<bool>, deque, and bitset as well as other data structures people might create like unrolled lists.
I say that in a way that goes beyond just armchair speculation, since I have a set of data structures which resemble the likes of deque which are actually on par with sequential iteration of vector (still noticeably slower for random-access, especially if we're just storing a bunch of primitives and doing trivial processing). However, to achieve the comparable times to vector for sequential iteration, I had to use these types of techniques (for_each method and double/nested iterators) to reduce the amount of processing and branching going on in each iteration. I could not rival the times otherwise using just the flat iterator design and/or operator[]. And I'm certainly not smarter than the standard library implementers but came up with a deque-like container which can be sequentially iterated much faster, and that strongly suggests to me that it's an issue with the standard interface design of iterators in this case which come with some overhead in these peculiar cases that the optimizer cannot optimize away.
Old Answer
I'm one of those who would give you a similar performance answer, but I'll try to give you something a bit more in-depth than "just because". It is something I came across through actual profiling and timing, not merely distrust and paranoia.
One of the biggest problems with bitset and vector<bool> is that their interface design is "too convenient" if you want to use them like an array of booleans. Optimizers are great at obliterating all that structure you establish to provide safety, reduce maintenance cost, make changes less intrusive, etc. They do an especially fine job with selecting instructions and allocating the minimal number of registers to make such code run as fast as the not-so-safe, not-so-easy-to-maintain/change alternatives.
The part that makes the bitset interface "too convenient" at the cost of efficiency is the random-access operator[] as well as the iterator design for vector<bool>. When you access one of these at index n, the code has to first figure out which byte the nth bit belongs to, and then the sub-index to the bit within that. That first phase typically involves a division/rshifts against an lvalue along with modulo/bitwise and which is more costly than the actual bit operation you're trying to perform.
The iterator design for vector<bool> faces a similar awkward dilemma where it either has to branch into different code every 8+ times you iterate through it or pay that kind of indexing cost described above. If the former is done, it makes the logic asymmetrical across iterations, and iterator designs tend to take a performance hit in those rare cases. To exemplify, if vector had a for_each method of its own, you could iterate through, say, a range of 64 elements at once by just masking the bits against a 64-bit mask for vector<bool> if all the bits are set without checking each bit individually. It could even use FFS to figure out the range all at once. An iterator design would tend to inevitably have to do it in a scalar fashion or store more state which has to be redundantly checked every iteration.
For random access, optimizers can't seem to optimize away this indexing overhead to figure out which byte and relative bit to access (perhaps a bit too runtime-dependent) when it's not needed, and you tend to see significant performance gains with that more manual code processing bits sequentially with advanced knowledge of which byte/word/dword/qword it's working on. It's somewhat of an unfair comparison, but the difficulty with std::bitset is that there's no way to make a fair comparison in such cases where the code knows what byte it wants to access in advance, and more often than not, you tend to have this info in advance. It's an apples to orange comparison in the random-access case, but you often only need oranges.
Perhaps that wouldn't be the case if the interface design involved a bitset where operator[] returned a proxy, requiring a two-index access pattern to use. For example, in such a case, you would access bit 8 by writing bitset[0][6] = true; bitset[0][7] = true; with a template parameter to indicate the size of the proxy (64-bits, e.g.). A good optimizer may be able to take such a design and make it rival the manual, old school kind of way of doing the bit manipulation by hand by translating that into: bitset |= 0x60;
Another design that might help is if bitsets provided a for_each_bit kind of method, passing a bit proxy to the functor you provide. That might actually be able to rival the manual method.
std::deque has a similar interface problem. Its performance shouldn't be that much slower than std::vector for sequential access. Yet unfortunately we access it sequentially using operator[] which is designed for random access or through an iterator, and the internal rep of deques simply don't map very efficiently to an iterator-based design. If deque provided a for_each kind of method of its own, then there it could potentially start to get a lot closer to std::vector's sequential access performance. These are some of the rare cases where that Sequence interface design comes with some efficiency overhead that optimizers often can't obliterate. Often good optimizers can make convenience come free of runtime cost in a production build, but unfortunately not in all cases.
Sorry!
Also sorry, in retrospect I wandered a bit with this post talking about vector<bool> and deque in addition to bitset. It's because we had a codebase where the use of these three, and particularly iterating through them or using them with random-access, were often hotspots.
Apples to Oranges
As emphasized in the old answer, comparing straightforward usage of bitset to primitive types with low-level bitwise logic is comparing apples to oranges. It's not like bitset is implemented very inefficiently for what it does. If you genuinely need to access a bunch of bits with a random access pattern which, for some reason or other, needs to check and set just one bit a time, then it might be ideally implemented for such a purpose. But my point is that almost all use cases I've encountered didn't require that, and when it's not required, the old school way involving bitwise operations tends to be significantly more efficient.
Related Topics
Add Object to Arraylist at Specified Index
Fatal Exception: Firebase-Messaging-Intent-Handle -- Java.Lang.Noclassdeffounderror
Multiple Typeface in Single Textview
Apache Http Client or Urlconnection
Reusing Views in Android Listview with 2 Different Layouts
Android: Cannot Perform This Operation Because the Connection Pool Has Been Closed
Android Color Between Two Colors, Based on Percentage
On Zoom Event for Google Maps on Android
Is Iterating Concurrenthashmap Values Thread Safe
Sending Message to Specific User on Spring Websocket
Convert from Enum Ordinal to Enum Type
Builder Pattern in Effective Java
Calculate Distance in Meters When You Know Longitude and Latitude in Java