Read from a file starting at the end, similar to tail
To read the last 1024 bytes:
using (var reader = new StreamReader("foo.txt"))
{
if (reader.BaseStream.Length > 1024)
{
reader.BaseStream.Seek(-1024, SeekOrigin.End);
}
string line;
while ((line = reader.ReadLine()) != null)
{
Console.WriteLine(line);
}
}
Get last n lines of a file, similar to tail
The code I ended up using. I think this is the best so far:
def tail(f, n, offset=None):
"""Reads a n lines from f with an offset of offset lines. The return
value is a tuple in the form ``(lines, has_more)`` where `has_more` is
an indicator that is `True` if there are more lines in the file.
"""
avg_line_length = 74
to_read = n + (offset or 0)
while 1:
try:
f.seek(-(avg_line_length * to_read), 2)
except IOError:
# woops. apparently file is smaller than what we want
# to step back, go to the beginning instead
f.seek(0)
pos = f.tell()
lines = f.read().splitlines()
if len(lines) >= to_read or pos == 0:
return lines[-to_read:offset and -offset or None], \
len(lines) > to_read or pos > 0
avg_line_length *= 1.3
Windows equivalent of the 'tail' command
No exact equivalent. However there exist a native DOS command "more" that has a +n option that will start outputting the file after the nth line:
DOS Prompt:
C:\>more +2 myfile.txt
The above command will output everything after the first 2 lines.
This is actually the inverse of Unix head:
Unix console:
root@server:~$ head -2 myfile.txt
The above command will print only the first 2 lines of the file.
How to follow the file starting with the end position (tail -fn 0) in Perl
You may want to enable warnings first,
use warnings;
and import seek constants (SEEK_END)
use Fcntl qw(:seek);
After that
seek(FH , -1 , SEEK_END) or warn "Can't seek";
will position your handle at one byte before last one, so use 0 instead of -1 if you wan't to go at the end of the file.
What is the best way to read last lines (i.e. tail) from a file using PHP?
Methods overview
Searching on the internet, I came across different solutions. I can group them
in three approaches:
- naive ones that use
file()PHP function; - cheating ones that runs
tailcommand on the system; - mighty ones that happily jump around an opened file using
fseek().
I ended up choosing (or writing) five solutions, a naive one, a cheating one
and three mighty ones.
- The most concise naive solution,
using built-in array functions. - The only possible solution based on
tailcommand, which has
a little big problem: it does not run iftailis not available, i.e. on
non-Unix (Windows) or on restricted environments that don't allow system
functions. - The solution in which single bytes are read from the end of file searching
for (and counting) new-line characters, found here. - The multi-byte buffered solution optimized for large files, found
here. - A slightly modified version of solution #4 in which buffer length is
dynamic, decided according to the number of lines to retrieve.
All solutions work. In the sense that they return the expected result from
any file and for any number of lines we ask for (except for solution #1, that can
break PHP memory limits in case of large files, returning nothing). But which one
is better?
Performance tests
To answer the question I run tests. That's how these thing are done, isn't it?
I prepared a sample 100 KB file joining together different files found in
my /var/log directory. Then I wrote a PHP script that uses each one of the
five solutions to retrieve 1, 2, .., 10, 20, ... 100, 200, ..., 1000 lines
from the end of the file. Each single test is repeated ten times (that's
something like 5 × 28 × 10 = 1400 tests), measuring average elapsed
time in microseconds.
I run the script on my local development machine (Xubuntu 12.04,
PHP 5.3.10, 2.70 GHz dual core CPU, 2 GB RAM) using the PHP command line
interpreter. Here are the results:
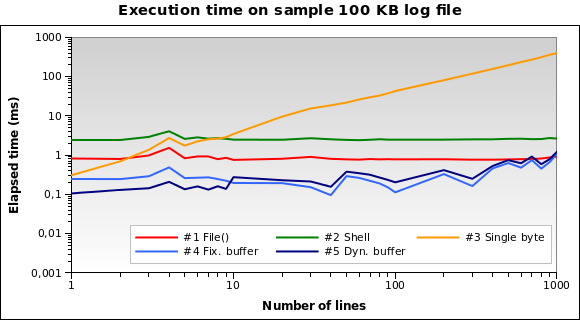
Solution #1 and #2 seem to be the worse ones. Solution #3 is good only when we need to
read a few lines. Solutions #4 and #5 seem to be the best ones.
Note how dynamic buffer size can optimize the algorithm: execution time is a little
smaller for few lines, because of the reduced buffer.
Let's try with a bigger file. What if we have to read a 10 MB log file?
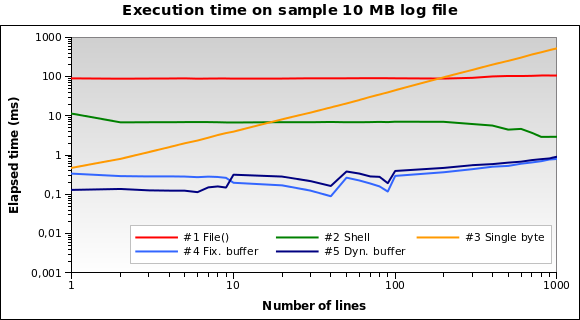
Now solution #1 is by far the worse one: in fact, loading the whole 10 MB file
into memory is not a great idea. I run the tests also on 1MB and 100MB file,
and it's practically the same situation.
And for tiny log files? That's the graph for a 10 KB file:
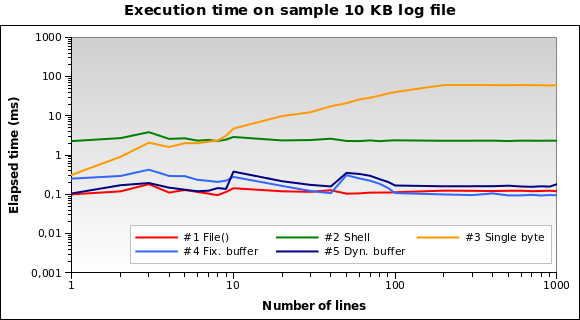
Solution #1 is the best one now! Loading a 10 KB into memory isn't a big deal
for PHP. Also #4 and #5 performs good. However this is an edge case: a 10 KB log
means something like 150/200 lines...
You can download all my test files, sources and results
here.
Final thoughts
Solution #5 is heavily recommended for the general use case: works great
with every file size and performs particularly good when reading a few lines.
Avoid solution #1 if you
should read files bigger than 10 KB.
Solution #2
and #3
aren't the best ones for each test I run: #2 never runs in less than
2ms, and #3 is heavily influenced by the number of
lines you ask (works quite good only with 1 or 2 lines).
How to read lines from a file in python starting from the end
The general approach to this problem, reading a text file in reverse, line-wise, can be solved by at least three methods.
The general problem is that since each line can have a different length, you can't know beforehand where each line starts in the file, nor how many of them there are. This means you need to apply some logic to the problem.
General approach #1: Read the entire file into memory
With this approach, you simply read the entire file into memory, in some data structure that subsequently allows you to process the list of lines in reverse. A stack, a doubly linked list, or even an array can do this.
Pros: Really easy to implement (probably built into Python for all I know)
Cons: Uses a lot of memory, can take a while to read large files
General approach #2: Read the entire file, store position of lines
With this approach, you also read through the entire file once, but instead of storing the entire file (all the text) in memory, you only store the binary positions inside the file where each line started. You can store these positions in a similar data structure as the one storing the lines in the first approach.
Whever you want to read line X, you have to re-read the line from the file, starting at the position you stored for the start of that line.
Pros: Almost as easy to implement as the first approach
Cons: can take a while to read large files
General approach #3: Read the file in reverse, and "figure it out"
With this approach you will read the file block-wise or similar, from the end, and see where the ends are. You basically have a buffer, of say, 4096 bytes, and process the last line of that buffer. When your processing, which has to move one line at a time backward in that buffer, comes to the start of the buffer, you need to read another buffer worth of data, from the area before the first buffer you read, and continue processing.
This approach is generally more complicated, because you need to handle such things as lines being broken over two buffers, and long lines could even cover more than two buffers.
It is, however, the one that would require the least amount of memory, and for really large files, it might also be worth doing this to avoid reading through gigabytes of information first.
Pros: Uses little memory, does not require you to read the entire file first
Cons: Much hard to implement and get right for all corner cases
There are numerous links on the net that shows how to do the third approach:
- ActiveState Recipe 120686 - Read a text file backwards
- ActiveState Recipe 439045 - Read a text file backwards (yet another implementation)
- Top4Download.com Script - Read a text file backwards
How to read a very huge file from the end in C#?
A Stream has long properties named Position and Length. You can set the Position to any value you like within the range [0, Length[, like fileStream.Position = fileStream.Length - 45;.
Or, you could use the Stream.Seek function: fileStream.Seek(-45, SeekOrigin.End).
Use the more readable one depending on the surrounding code and situation, the one that best conveys your intention.
Here's some code:
using (var fileStream = File.OpenRead("myfile.txt"))
using (var streamReader = new StreamReader(fileStream, Encoding.ASCII))
{
if (fileStream.Length >= 45)
fileStream.Seek(-45, SeekOrigin.End);
var value = streamReader.ReadToEnd(); // Last 45 chars;
}
This is easier since you know your file is encoded in ASCII. Otherwise, you'd have to read a bit of text from the start of the file with the reader to let it detect the encoding (if a BOM is present), and only then seek to the position you want to read from.
How to read last n lines of log file
Your code will perform very poorly, since you aren't allowing any caching to happen.
In addition, it will not work at all for Unicode.
I wrote the following implementation:
///<summary>Returns the end of a text reader.</summary>
///<param name="reader">The reader to read from.</param>
///<param name="lineCount">The number of lines to return.</param>
///<returns>The last lneCount lines from the reader.</returns>
public static string[] Tail(this TextReader reader, int lineCount) {
var buffer = new List<string>(lineCount);
string line;
for (int i = 0; i < lineCount; i++) {
line = reader.ReadLine();
if (line == null) return buffer.ToArray();
buffer.Add(line);
}
int lastLine = lineCount - 1; //The index of the last line read from the buffer. Everything > this index was read earlier than everything <= this indes
while (null != (line = reader.ReadLine())) {
lastLine++;
if (lastLine == lineCount) lastLine = 0;
buffer[lastLine] = line;
}
if (lastLine == lineCount - 1) return buffer.ToArray();
var retVal = new string[lineCount];
buffer.CopyTo(lastLine + 1, retVal, 0, lineCount - lastLine - 1);
buffer.CopyTo(0, retVal, lineCount - lastLine - 1, lastLine + 1);
return retVal;
}
How to start from the last line with tail?
Note you are saying tail -n +1 "$log", which is interpreted by tail as: start reading from line 1. So you are in fact doing cat "$log".
You probably want to say tail -n 1 "$log" (without the + before 1) to get the last n lines.
Also, if you want to get the last match of $something, you may want to use tac. This prints a file backwards: first the last line, then the penultimate... and finally the first one.
So if you do
tac "$log" | grep -m1 "$something"
this will print the last match of $something and then exit, because -mX prints the first X matches.
Or of course you can use awk as well:
tac "$log" | awk -v pattern="$something" '$9 ~ pattern {print; exit}'
Note the usage of -v to give to awk the variable. This way you avoid a confusing mixure of single and double quotes in your code.
Related Topics
Entity Framework - Stored Procedure Return Value
The Connection Was Not Closed the Connection's Current State Is Open
Detect Windows Font Size (100%, 125%, and 150%)
C# - Making All Derived Classes Call the Base Class Constructor
Xmlserializer Serialize Generic List of Interface
How to Retrieve a List of Parameters from a Stored Procedure in SQL Server
How to Generically Format a Boolean to a Yes/No String
Stack Overflow Exception in C# Setter
Can a Picturebox Show Animated Gif in Windows Application
Copy Values from One Object to Another
How to Recognize If a String Contains Unicode Chars
Show Transparent Loading Spinner Above Other Controls
Simulating Cross Context Joins--Linq/C#
How to Output Unicode String to Rtf (Using C#)
Adding Custom Properties for Each Request in Application Insights Metrics