Pretty-print an entire Pandas Series / DataFrame
You can also use the option_context, with one or more options:
with pd.option_context('display.max_rows', None, 'display.max_columns', None): # more options can be specified also
print(df)
This will automatically return the options to their previous values.
If you are working on jupyter-notebook, using display(df) instead of print(df) will use jupyter rich display logic (like so).
Pretty print a pandas dataframe in VS Code
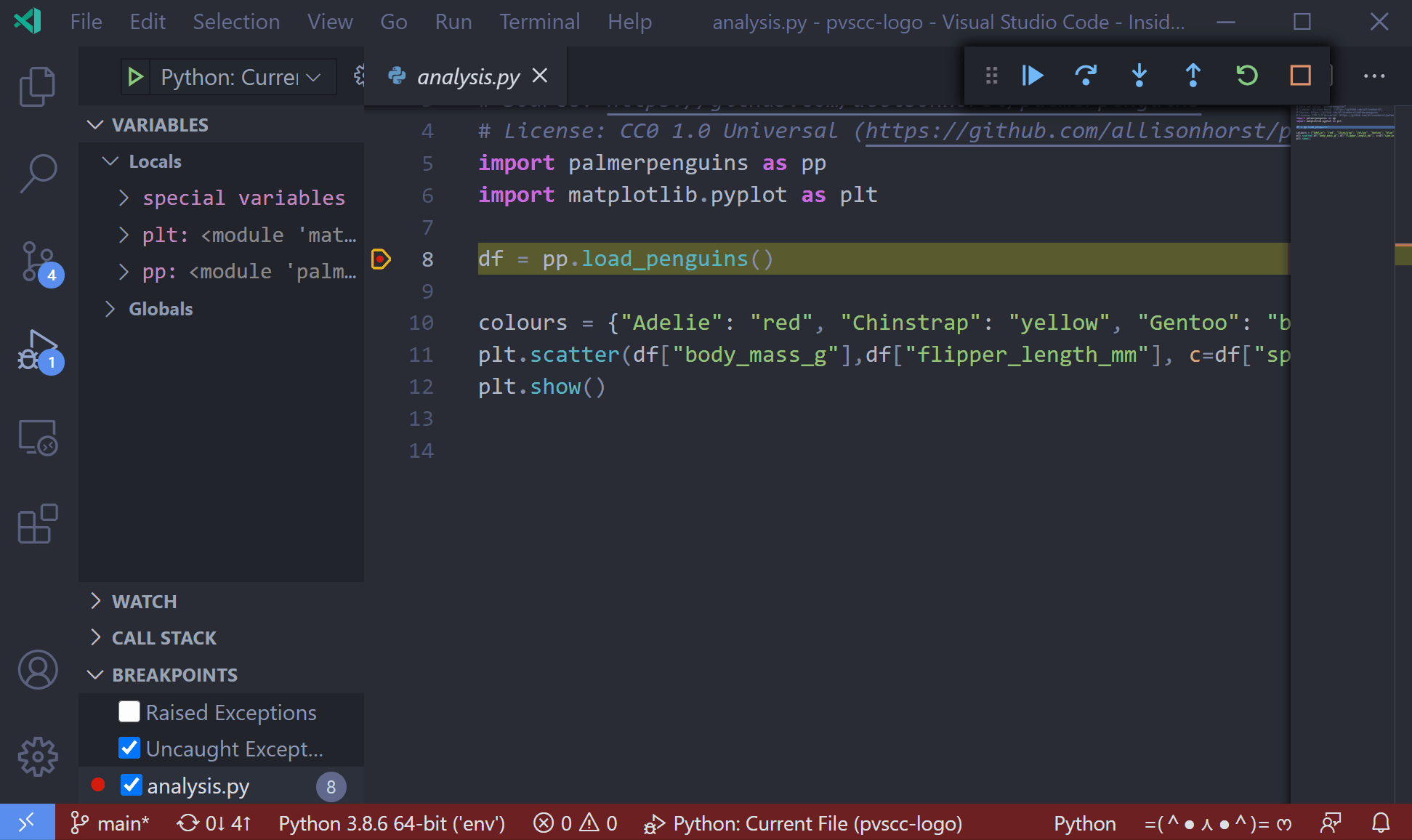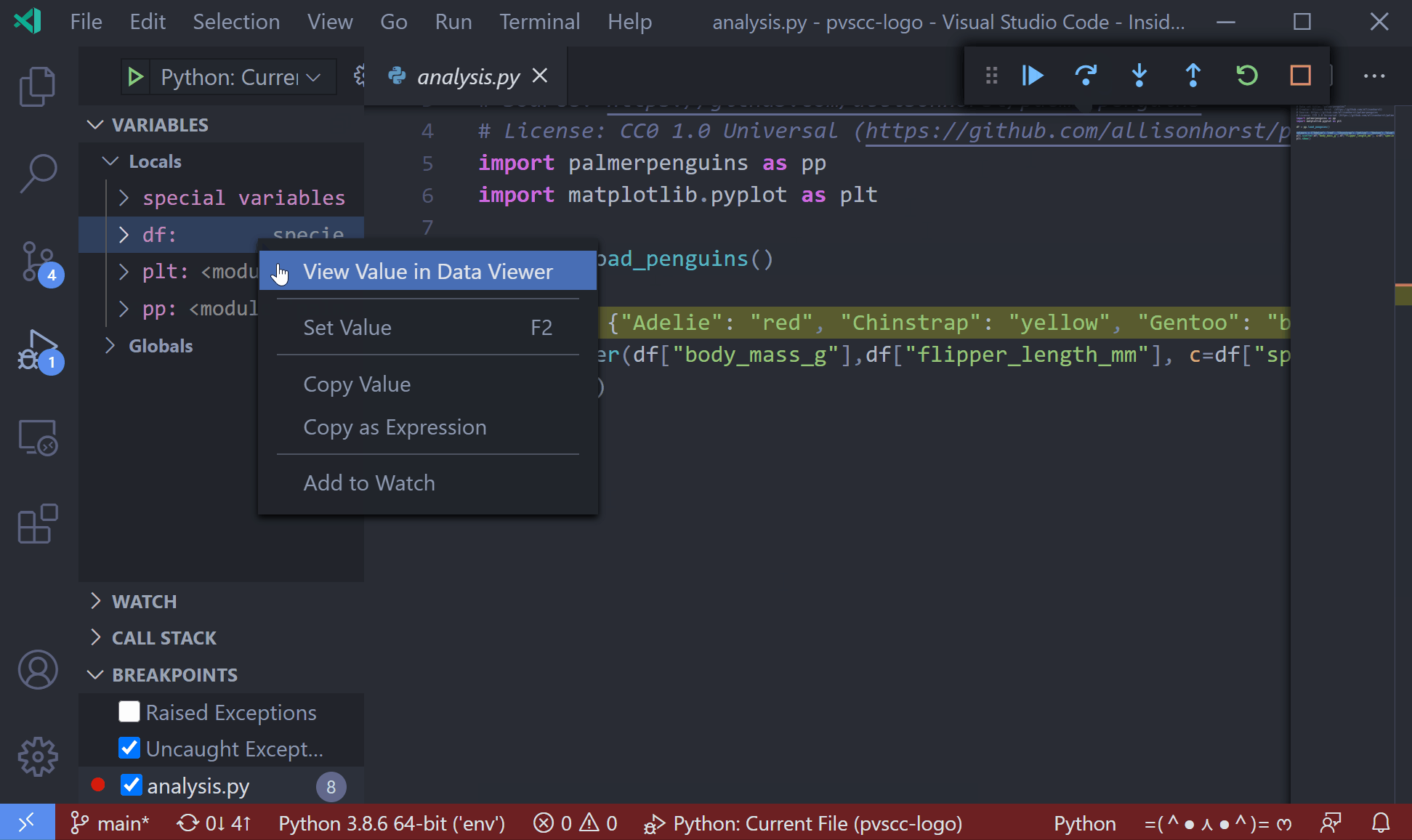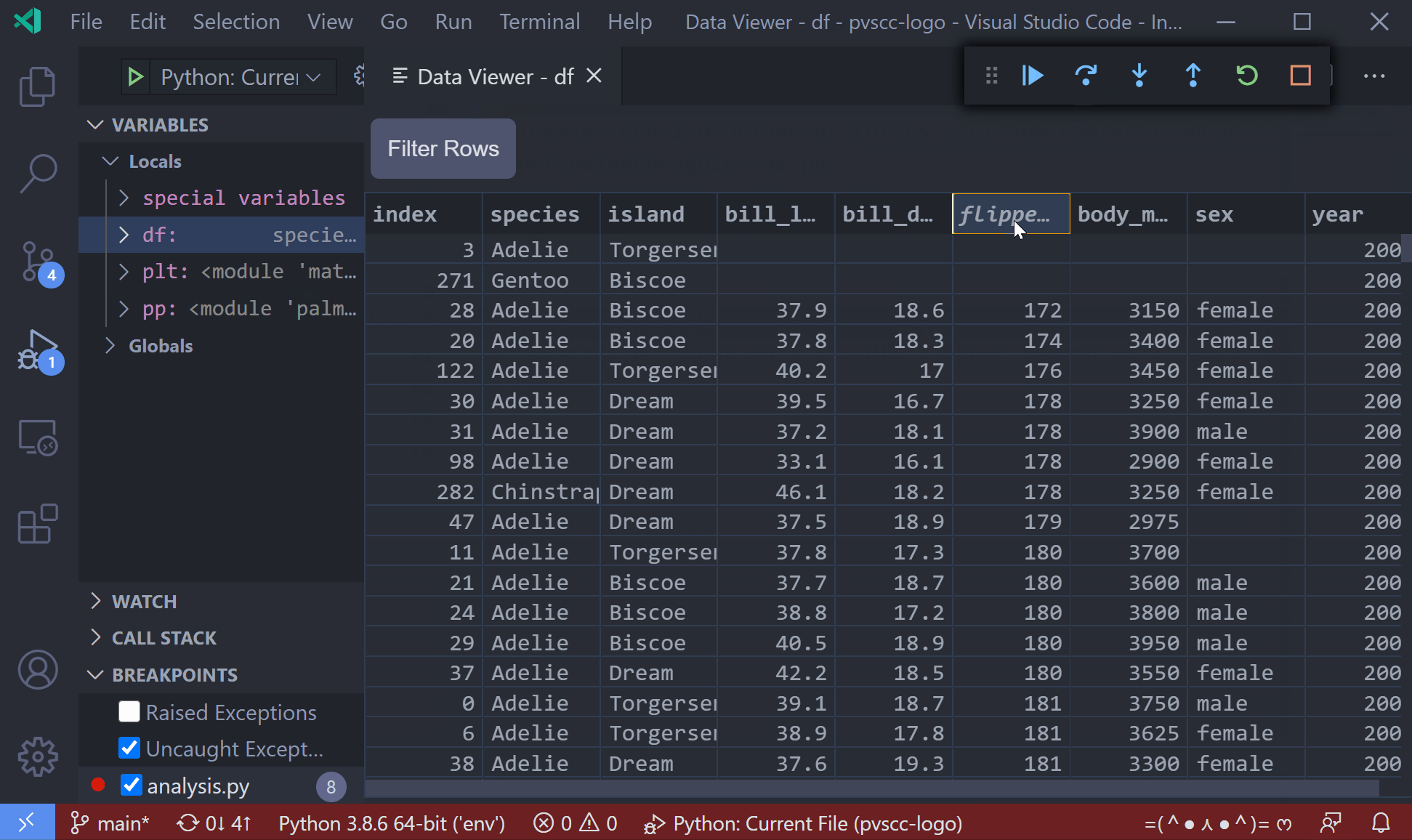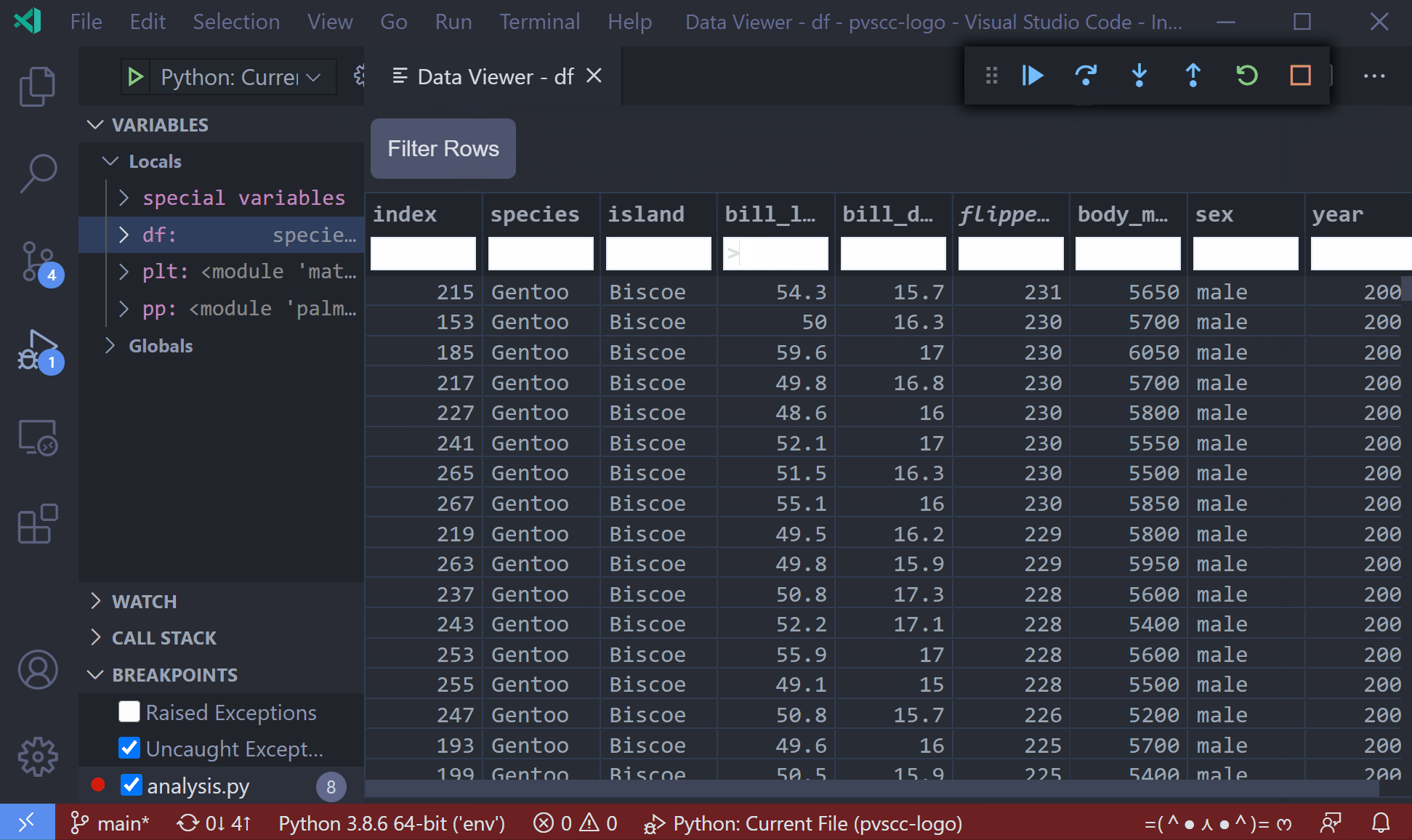
As of the January 2021 release of the python extension, you can now view pandas dataframes with the built-in data viewer when debugging native python programs. When the program is halted at a breakpoint, right-click the dataframe variable in the variables list and select "View Value in Data Viewer"
Instead of printing to console create a dataframe for output
I am making several assumptions here to include:
Compare.txt is a text file consisting of a list of single words 1 word per line.
Source.txt is a free flowing text file, which includes multiple words per line and each word is separated by a space.
When comparing to determine if a compare word is in source, is is found if and only if, no punctuation marks (i.e. " ' , . ?, etc) are appended to the word in source .
The output dataframe will only contain the words found in compare.txt.
The final output is a printed version of the pandas dataframe.
With these assumptions:
import pandas as pd
from collections import defaultdict
compare = 'compare.txt'
source = 'source.txt'
rslt = defaultdict(list)
def getCompareTxt(fid: str) -> list:
clist = []
with open(fid, 'r') as cmpFile:
for line in cmpFile.readlines():
clist.append(line.lower().strip('\n'))
return clist
cmpList = getCompareTxt(compare)
if cmpList:
with open(source, 'r') as fsrc:
items = []
for item in (line.strip().split(' ') for line in fsrc):
items.extend(item)
print(items)
for cmpItm in cmpList:
rslt['Name'].append(cmpItm)
if cmpItm in items:
rslt['State'].append('Present')
else:
rslt['State'].append('Not Present')
df = pd.DataFrame(rslt, index=range(len(cmpList)))
print(df)
else:
print('No compare data present')
Related Topics
Run a .Bat File Using Python Code
Merging Several Python Dictionaries
Color by Column Values in Matplotlib
Finding a Key Recursively in a Dictionary
How to Extract All the Emojis from Text
Reconstruct a Categorical Variable from Dummies in Pandas
How to Make Program Go Back to the Top of the Code Instead of Closing
What's the Deal with Python 3.4, Unicode, Different Languages and Windows
List on Python Appending Always the Same Value
Cartesian Product of Two Lists in Python
Execute Multiple Commands in Paramiko So That Commands Are Affected by Their Predecessors
Making the Background Move Sideways in Pygame
Python CSV Error: Line Contains Null Byte
Pandas Select from Dataframe Using Startswith