Getting the bounding box of the recognized words using python-tesseract
Use pytesseract.image_to_data()
import pytesseract
from pytesseract import Output
import cv2
img = cv2.imread('image.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['level'])
for i in range(n_boxes):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
Among the data returned by pytesseract.image_to_data():
leftis the distance from the upper-left corner of the bounding
box, to the left border of the image.topis the distance from the upper-left corner of the bounding box,
to the top border of the image.widthandheightare the width and height of the bounding box.confis the model's confidence for the prediction for the word within that bounding box. Ifconfis -1, that means that the corresponding bounding box contains a block of text, rather than just a single word.
The bounding boxes returned by pytesseract.image_to_boxes() enclose letters so I believe pytesseract.image_to_data() is what you're looking for.
Easily readable text not recognized by tesseract
Use these updated data files.
This guide criticizes out-of-the box performance (and maybe the accuracy could be affected too):
Trained data. On the moment of writing, tesseract-ocr-eng APT package for Ubuntu 18.10 has terrible out of the box performance, likely because of corrupt training data.
According to the following test I did, using the updated data files seems to provide better results. This is the code I used:
import pytesseract
from PIL import Image
print(pytesseract.image_to_string(Image.open('farmacias.jpg'), lang='spa', config='--tessdata-dir ./tessdata --psm 7'))
I downloaded spa.traineddata (your example images have Spanish words, right?) to ./tessdata/spa.traineddata. And the result was:
ARMACIAS
And for the second image:
PECIALIZADA:
I used --psm 7 because here it says that it means "Treat the image as a single text line" and I thought that should make sense for your test images.
In this Google Colab you can see the test I did.
How do I segment a document using Tesseract then output the resulting bounding boxes and labels
Success. Many thanks to the people at the Pattern Recognition and Image Analysis Research Lab (PRImA) for producing tools to handle this. You can obtain them freely on their website or github.
Below I give the full solution for a Mac running 10.10 and using the homebrew package manager. I use wine to run windows executables.
Overview
- Download tools: Tesseract OCR to Page (TPT) and Page Viewer (PVT)
- Use the TPT to run tesseract on your document and convert the HOCR xml to a PAGE xml
- Use the PVT to view the original image with the PAGE xml information overlaid
Code
brew install wine # takes a little while >10m
brew install gs # only for generating a tif example. Not required, you can use Preview
brew install wget # only for downloading example paper. Not required, you can do so manually!
cd ~/Downloads
wget -O paper.pdf "http://www.prima.cse.salford.ac.uk/www/assets/papers/ICDAR2013_Antonacopoulos_HNLA2013.pdf"
# This command can be ommitted and you can do the conversion to tiff with Preview
gs \
-o paper-%d.tif \
-sDEVICE=tiff24nc \
-r300x300 \
paper.pdf
cd ~/Downloads
# ttptool is the location you downloaded the Tesseract to PAGE tool to
ttptool="/Users/Me/Project/tools/TesseractToPAGE 1.3"
# sudo chmod 777 "$ttptool/bin/PRImA_Tesseract-1-3-78.exe"
touch "$ttptool/log.txt"
wine "$ttptool/bin/PRImA_Tesseract-1-3-78.exe" \
-inp-img "$dl/Downloads/paper-3.tif" \
-out-xml "$dl/Downloads/paper-3-tool.xml" \
-rec-mode layout>>log.txt
# pvtool is the location you downloaded the PAGE Viewer tool to
pvtool="/Users/Me/Project/tools/PAGEViewerMacOS_1.1/JPageViewer 1.1 (Mac OS, 64 bit)"
cd "$pvtool"
dl=~
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3-tool.xml" "$dl/Downloads/paper-3.tif"
Results
Document with overlays (rollover to see text and type)
Overlays alone (use GUI buttons to toggle)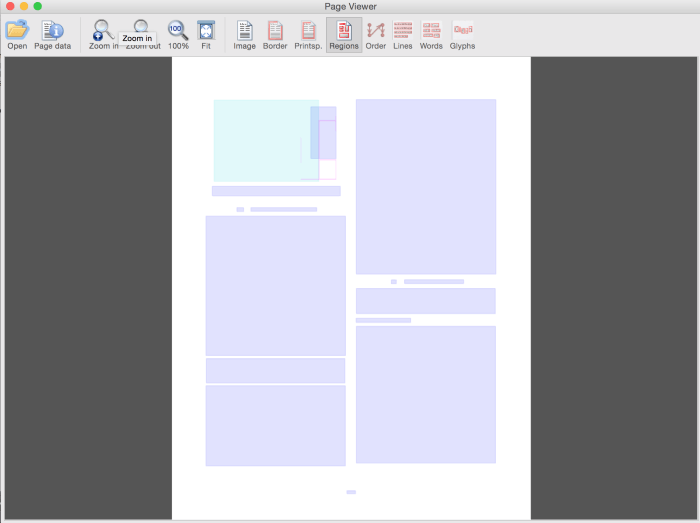
Appendix
You can run tesseract yourself and use another tool to convert its output to PAGE format. I was unable to get this to work but I'm sure you'll be fine!
# Note that the pvtool does take as input HOCR xml but it ignores the region type
brew install tesseract --devel # installs v 3.03 at time of writing
tesseract ~/Downloads/paper-3.tif ~/Downloads/paper-3 hocr
mv paper-3.hocr paper-3.xml # The page viewer will only open XML files
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3.xml"
At this point you need to use the PAGE Converter Java Tool to convert the HOCR xml into a PAGE xml. It should go a little something like this:
pctool="/Users/Me/Project/tools/JPageConverter 1.0"
java -jar "$pctool/PageConverter.jar" -source-xml paper-3.xml -target-xml paper-3-hocrconvert.xml -convert-to LATEST
Unfortunately, I kept getting null pointers.
Could not convert to target XML schema format.
java.lang.NullPointerException
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:126)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
Could not save target PAGE XML file: paper-3-hocrconvert.xml
java.lang.NullPointerException
at org.primaresearch.dla.page.io.xml.XmlInputOutput.writePage(XmlInputOutput.java:144)
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:135)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
Related Topics
Windowserror: [Error 126] the Specified Module Could Not Be Found
Valueerror: X and Y Must Be the Same Size
How to Get the Coordinates of the Bounding Box in Yolo Object Detection
How to Downgrade Tensorflow, Multiple Versions Possible
Permissionerror: [Errno 13] Permission Denied Flask.Run()
Opencv Typeerror: Expected Cv::Umat for Argument 'Src' - What Is This
Sort Array and Return Original Indexes of Sorted Array
Get Row Value of Maximum Count After Applying Group by in Pandas
Python3: How to Print Out User Input String and Print It Out Separated by a Comma
Use Tqdm Progress Bar With Pandas
Loading All Images Using Imread from a Given Folder
Pandas: Sum Dataframe Rows for Given Columns
Valueerror: Invalid \Escape Unable to Load Json from File
How to Use Ffmpeg in a Python Function
Beautifulsoup: Get the Contents of a Specific Table
How to Split by Commas That Are Not Within Parentheses
Finding Length of the Longest List in an Irregular List of Lists