What is the difference between `sorted(list)` vs `list.sort()`?
sorted() returns a new sorted list, leaving the original list unaffected. list.sort() sorts the list in-place, mutating the list indices, and returns None (like all in-place operations).
sorted() works on any iterable, not just lists. Strings, tuples, dictionaries (you'll get the keys), generators, etc., returning a list containing all elements, sorted.
Use
list.sort()when you want to mutate the list,sorted()when you want a new sorted object back. Usesorted()when you want to sort something that is an iterable, not a list yet.For lists,
list.sort()is faster thansorted()because it doesn't have to create a copy. For any other iterable, you have no choice.No, you cannot retrieve the original positions. Once you called
list.sort()the original order is gone.
What's the difference between list interface sort method and stream interface sorted method?
If you wish to known which is best, your best option is to benchmark it: you may reuse my answer JMH test.
It should be noted that:
List::sortuseArrays::sort. It create an array before sorting. It does not exists for otherCollection.Stream::sortedis done as state full intermediate operation. This means theStreamneed to remember its state.
Without benchmarking, I'd say that:
- You should use
collection.sort(). It is easier to read:collection.stream().sorted().collect(toList())is way to long to read and unless you format your code well, you might have an headache (I exaggerate) before understanding that this line is simply sorting. sort()on aStreamshould be called:- if you filter many elements making the
Streameffectively smaller in size than the collection (sorting N items then filtering N items is not the same than filtering N items then sorting K items with K <= N). - if you have a map transformation after the sort and you loose a way to sort using the original key.
- if you filter many elements making the
If you use your stream with other intermediate operation, then sort might be required / useful:
collection.stream() // Stream<U> #0
.filter(...) // Stream<U> #1
.sorted() // Stream<U> #2
.map(...) // Stream<V> #3
.collect(toList()) // List<V> sorted by U.
;
In that example, the filter apply before the sort: the stream #1 is smaller than #0, so the cost of sorting with stream might be less than Collections.sort().
If all that you do is simply filtering, you may also use a TreeSet or a collectingAndThen operation:
collection.stream() // Stream<U> #0
.filter(...) // Stream<U> #1
.collect(toCollection(TreeSet::new))
;
Or:
collection.stream() // Stream<U>
.filter(...) // Stream<U>
.collect(collectingAndThen(toList(), list -> {
list.sort();
return list;
})); // List<V>
Difference between Collections.sort(list) and list.sort(Comparator)
The method List.sort(comparator) that you are refering to was introduced in Java 8, whereas the utility method Collections.sort has been there since Java 1.2.
As such, you will find a lot of reference on the Internet mentioning that utility method but that's just because it has been in the JDK for a lot longer.
Note that the change in implementation for Collections.sort was made in 8u20.
what's the difference between list.sort and std::sort?
std::sort requires random access iterators, which std::list does not provide. Consequently, std::list and std::forward_list implement their own member functions for sorting which work with their weaker iterators. The complexity guarantees of those member functions are worse than those of the more efficient general algorithm.[Whoops: see comments.]
Moreover, the member functions can take advantage of the special nature of the list data structure by simply relinking the list nodes, while the standard algorithm has to perform something like swap (or something to that effect), which requires object construction, assignment and deletion.
Note that remove() is a similar case: The standard algorithm is merely some iterator-returning rearrangement, while the list member function performs the lookup and actual removal all in one go; again thanks to being able to take advantage of the knowledge of the list's internal structure.
Sorted list difference
Spearman's rho
I think what you want is Spearman's rank correlation coefficient. Using the index [rank] vectors for the two sortings (perfect A and approximate B), you calculate the rank correlation rho ranging from -1 (completely different) to 1 (exactly the same):
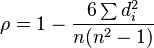
where d(i) are the difference in ranks for each character between A and B
You can defined your measure of error as a distance D := (1-rho)/2.
What's the difference between SortedList and SortedDictionary?
Yes - their performance characteristics differ significantly. It would probably be better to call them SortedList and SortedTree as that reflects the implementation more closely.
Look at the MSDN docs for each of them (SortedList, SortedDictionary) for details of the performance for different operations in different situtations. Here's a nice summary (from the SortedDictionary docs):
The
SortedDictionary<TKey, TValue>generic
class is a binary search tree with
O(log n) retrieval, where n is the
number of elements in the dictionary.
In this, it is similar to the
SortedList<TKey, TValue>generic
class. The two classes have similar
object models, and both have O(log n)
retrieval. Where the two classes
differ is in memory use and speed of
insertion and removal:
SortedList<TKey, TValue>uses less
memory thanSortedDictionary<TKey,.
TValue>
SortedDictionary<TKey, TValue>has
faster insertion and removal
operations for unsorted data, O(log n)
as opposed to O(n) for
SortedList<TKey, TValue>.If the list is populated all at once
from sorted data,SortedList<TKey,is faster than
TValue>
SortedDictionary<TKey, TValue>.
(SortedList actually maintains a sorted array, rather than using a tree. It still uses binary search to find elements.)
python Difference between reversed(list) and list.sort(reverse=True)
You have hit on exactly the difference. Since Timsort is stable, sorting on the reverse versus reversing the sort will leave the unsorted elements in reverse orders.
>>> s = ((2, 3, 4), (1, 2, 3), (1, 2, 2))
>>> sorted(s, key=operator.itemgetter(0, 1), reverse=True)
[(2, 3, 4), (1, 2, 3), (1, 2, 2)]
>>> list(reversed(sorted(s, key=operator.itemgetter(0, 1))))
[(2, 3, 4), (1, 2, 2), (1, 2, 3)]
Related Topics
How to Extract a Floating Number from a String
Beautiful Soup: 'Resultset' Object Has No Attribute 'Find_All'
Environment Variables When Script Run by Cron
Allowing Ctrl-C to Interrupt a Python C-Extension
Python Sigkill Catching Strategies
How to Download Python from Command-Line
Python Multiprocessing Pool.Apply_Async with Shared Variables (Value)
Running Simulation with Hyperthreading Doubles Runtime
Modulenotfounderror: No Module Named 'Pydip', Although It's Installed
Sieve of Eratosthenes - Finding Primes Python
How to Change a Global Variable from Within a Function
Read File with Timeout in Python
Mismatch Between Sys.Executable and Sys.Version in Python
Running Python Script as a Systemd Service